Scribd has a variety of content to offer and connecting our users with their desired content is a crucial aspect of our product. One of the main ways that users find content on Scribd is through search, and in this post I want to delve into an analysis we did regarding parsing out valuable information from a user’s query in order to better serve them relevant results, and also learn more about what they are searching for.
The Opportunity
This is essentially a goldmine, where we can not only explore improvements to the underlying model that serves search results, but also pull in the product and design teams to create the best search experience possible, as well as inform our content acquisition team on what to pursue next. I will highlight a few areas that I personally find interesting and useful that connect Scribd’s various departments across the company.
Our search infrastructure has a few components that could benefit from being able to parse out relevant information in the query. One of which is boosting relevant content types (books, audiobooks, etc) if certain keywords appear in the user’s query. Whenever a user searches at Scribd, we have to make a decision on how to rank each row of content, essentially giving a priority to specific content based on a combined score from Elasticsearch and a gradient boosting model. If we can flag that that the user is searching for an audiobook, for example, we can rank the audiobook first instead of a book, or even show them only audiobooks. This should help get the user to the correct or relevant content as fast as possible, which hopefully creates an enjoyable experience for them.
Another way that this can help serve search results is if we can generate extra, relevant search results based on being able to identify specific parts of the query. Imagine a user’s query is “power systems chomsky”. The user is specifically after the title “Power Systems”, but might also be interested in other titles by Chomsky. Instead of bringing forward other titles that have similar words, we can say, “Hey, here’s Power Systems, but check out all these other great books from Noam Chomsky that we have”. Below is an illustration how how it might be hard to get to explore other title’s by Chomsky:
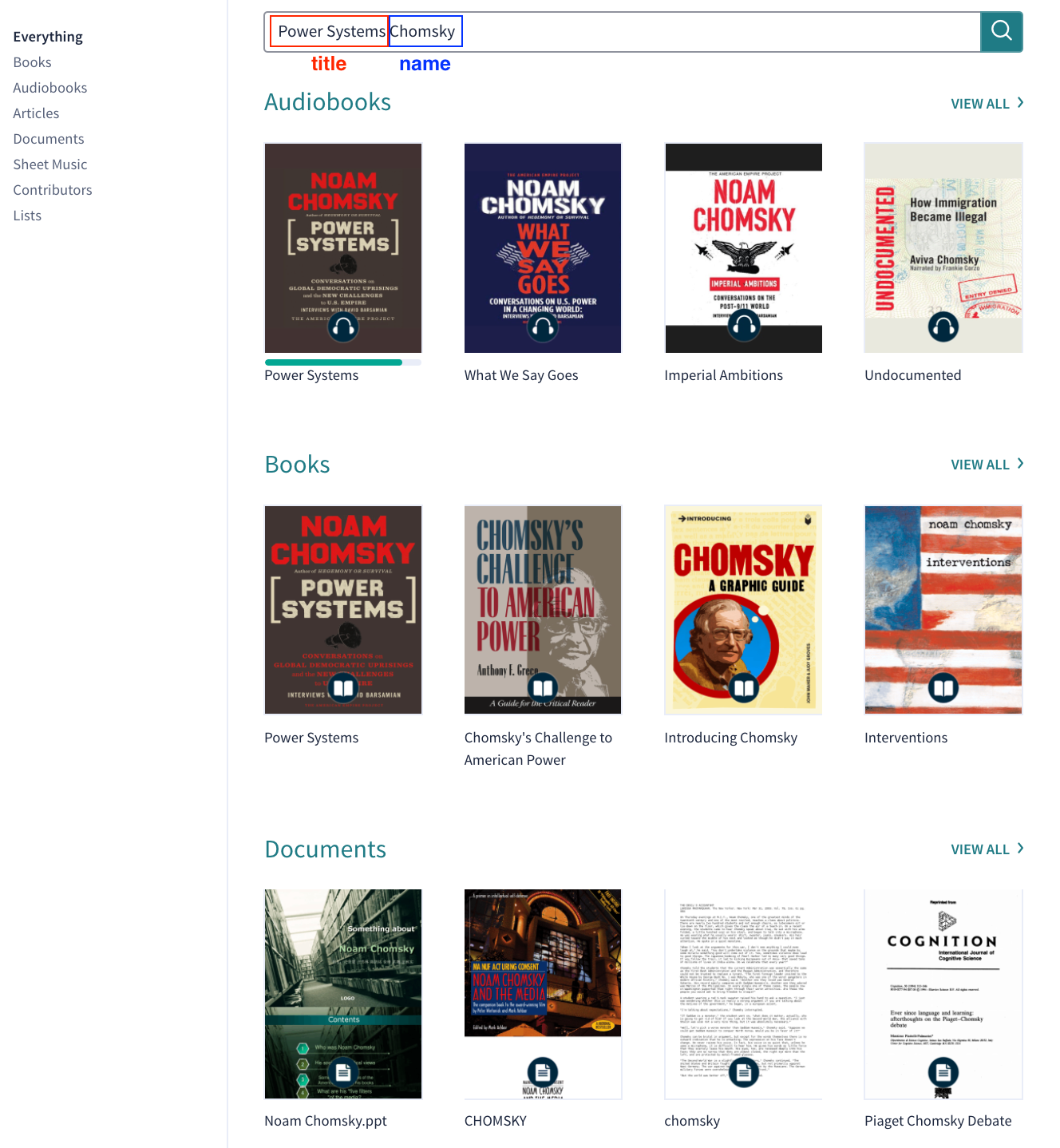
The opportunity is lost on these top results to show that we have other books by Chomsky, which you would have to scroll down to the bottom of the page to find:
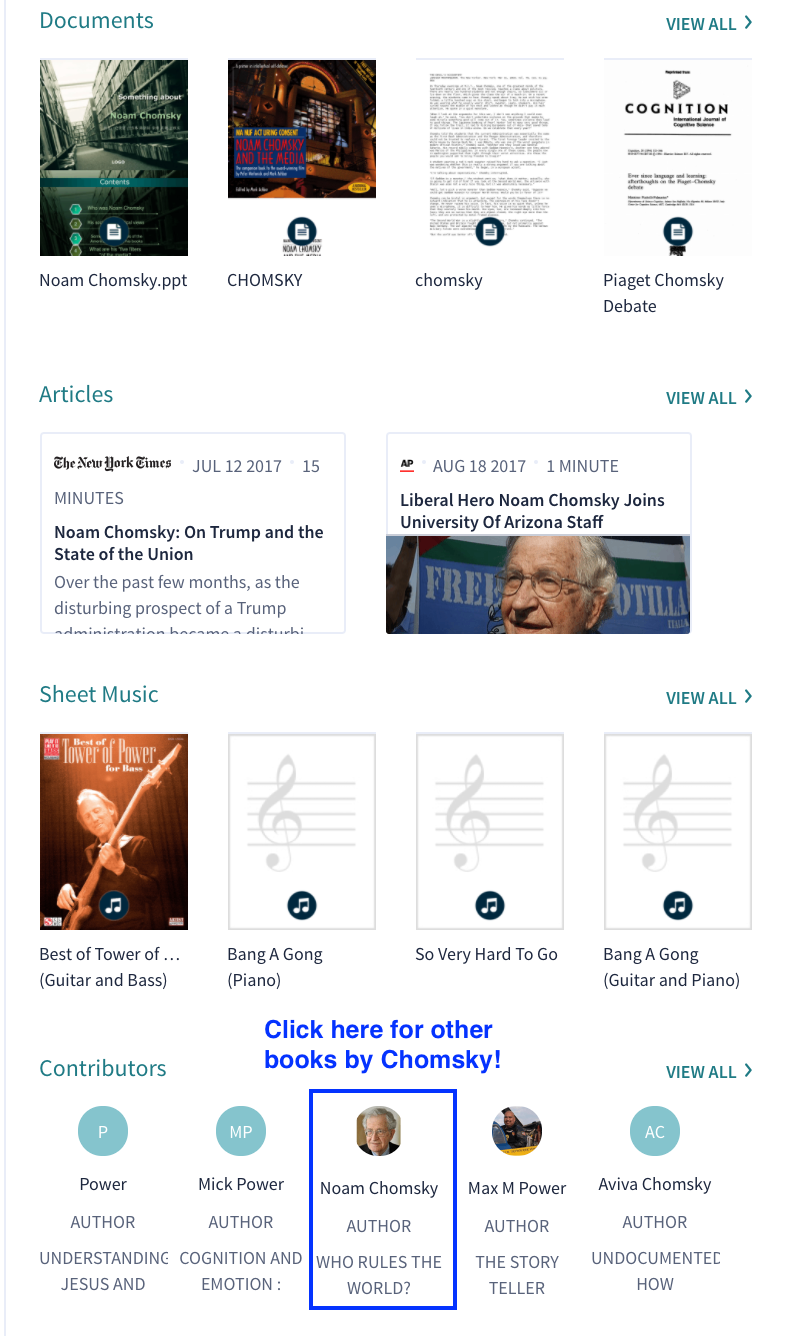
This can communicate to the user that we understand their search, and we have something additional that’s relevant to offer, which again adds to the relationship we are striving for with our users.
A final example is that this can help to inform our content acquisition team. Right now we have two ways of looking to see what unavailable content we have on Scribd that users are searching for. The first is simply to rank the queries based on how frequently they are searched for, and then manually go through and see what looks like a title we don’t have or an author we are missing, which is quite time consuming since it’s a manual process. The second is to look at unavailable titles that are surfaced during search and look at the most frequent ones. This works, but it means we have to have that book in our system. For example, we don’t carry any of the Harry Potter series (at the time this post was written) and this title is not a part of our unknown book database, so this method would never tell us that we should add any of Harry Potter books to our catalog. Being able to flag and parse out author and title entities from the rest of the query allows us to explore not only what titles are the most popular, but also what authors and which ones we are missing. This is still a somewhat manual process, but it segments the data in a convenient way such that our content team can easily filter through the results.
Approach
After seeing the power of seq2seq for spelling corrections we decided to try that model framework for this problem as well. As a quick reminder, the basic setup is an encoder and a decoder, which consist of memory cells (LSTM/GRU) that help the network to remember long sequences. An example of architecture can be found below
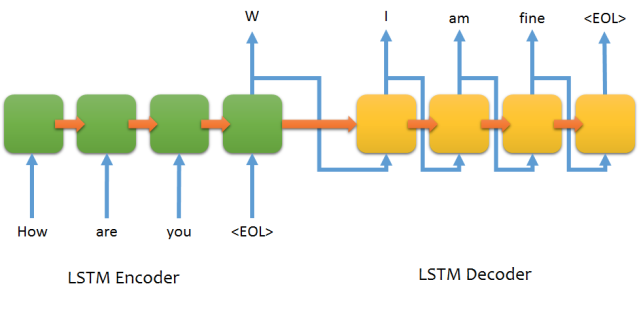
For this case, the input would be tokenized words from the user query, and the output would be each word with an associated tag putting it into a predefined category. The categories are:
-
name
-
title
-
topic
-
publication
-
publisher
-
content type
So, for example, the input query “Power Systems Chomsky” should output “title title name”. Then in our search framework we could serve “Power Systems” as well as all other books/audiobooks we have by or about Chomsky.
The final model architecture chosen uses an embedding input layer followed by two bidirectional LSTMs for the encoder and two for the decoder. The output is run through a softmax activation layer. The model is defined in keras below:
This model was exported to tensorflow so that we could easily incorporate it as part of our go microservice.
Training and Results
The data used to train this model comes from Scribd’s data warehouse which includes titles, authors, topics, publishers, and publications. A hand curated list of useful content types was used, factoring in different user spellings (eg. audiobook and audio book). This content was then combined to create training, test, and validation datasets. These datasets contain both single tag entries (eg. only title words) and also double tag entries (eg. title and content type words, name and title words, etc). Some examples are given below:
-
forbidden love series, title title title
-
selina hastings, name name
-
audiobooks inspirational devotional, content_type topic topic
-
the last virgin from las vegas geoff benge, title title title title title title name name
Note: I mixed these randomly, so the author doesn’t necessarily have to be associated with the book. This was a choice motivated by the fact that I don’t really care if the model learns the correct title author matches, just that it can identify which parts are title like and which are author (name) like. An interesting follow up would be to keep the correct author with the book, and see if this performs better.
The training set consists of 3 million entries, and the validation and test sets are much smaller, around 4k each. The vocabulary of the model is limited to the top 100k most frequently appearing words, and any unknown word is labeled as unknown.
The training was performed on a g2.2xlarge AWS instance. It ran for 30 epochs, which took approximately 12 hours and reached 96% accuracy on the test set. Here accuracy is defined as the number of entries that the model predicts all of the correct tags. For example, if the model predicts “title title title” for “power systems chomsky”, that would be marked as incorrect.
This model scores great on well formed data, but our user’s queries are not well formed, meaning they contain spelling errors, sparse information, and different languages. I hand scored 100 user queries to get an idea on how well it performs on real word data, and I found an accuracy of 70%, which is good enough for us to get this into production and test the impact on our users.
Future Iterations and Final Thoughts
We are in the process of getting this into production and will begin experimenting with the different ways in which we can utilize the output of this model to create a better search experience. However, there are still a few ways we can iterate on this model in order to improve:
-
Expand the tag categories to include things like ‘series’ (eg. Game of Thrones). This was overlooked and these end up in the title bucket.
-
Expand the vocabulary used, which should help to reduce the amount of guesswork involved in unknown words.
-
Correcting spelling would be a huge help, and would likely lead to better segmentation by mapping all words into vocabulary.
-
Reduce contamination between tag groups. We actually have an author named Harry Potter, however this is likely not what users are after when they search this term. Removing ambiguity with a more carefully crafted training set will help to reduce this issue.
I’m excited to see the results and will do a follow up post regarding the results and what we learned in the future. Stay tuned!