
Scribd offers a variety of publisher and user-uploaded content to our users and while the publisher content is rich in metadata, user-uploaded content typically is not. Documents uploaded by the users have varied subjects and content types which can make it challenging to link them together. One way to connect content can be through a taxonomy - an important type of structured information widely used in various domains. In this series, we have already shared how we identify document types and extract information from documents, this post will discuss how insights from data were used to help build the taxonomy and our approach to assign categories to the user-uploaded documents.
Building the taxonomy
The unified taxonomy is a tree-structure with two layers that was designed by combining our Subject Matter Experts’ (SME) knowledge of the book industry subject headings (BISAC categories) and data-driven insights. We used user-reading patterns to find topics that could help enrich our unified taxonomy.
Data-Driven Insights
Users have been interacting with Scribd content for more than 10 years, building reading patterns throughout time. We leveraged these reading patterns to create dense vector representations of documents similarly to word2vec in text.

For this work we focused only on user uploaded documents and on one type of interaction (reading for a minimum amount of time). The embeddings dimensions (and other hyperparamenters) were chosen to optimize the hit-ratio@20 (Caselles-Dupré, et al 2018) increasing how semantically tight the embeddings are.
Now that we have the embeddings we would like to use them to find groups of documents with similar subjects and topics. Finding these groups will help us identify categories that should be added to the taxonomy.
Dimensionality reduction allows for dense clusters of documents to be found more efficiently and accurately in the reduced space in comparison to the original high-dimensional space of our embeddings. We reduced the dimension of the embeddings using the t-SNE algorithm. t-SNE has a non-linear approach that can capture the smaller relationships between the points, as well as the global structure of the data. We used an implementation of t-SNE (Fast Fourier Transform accelerated Interpolation-based t-SNE” - FIt-SNE) that is flexible and does not sacrifice accuracy for speed.
Finally, we grouped the user-uploaded docs by clustering the reduced embeddings using HDBSCAN. HDBSCAN separates data points into clusters based on the density distribution. It also has a feature to detect noise, which are points that are too far from the nearest detected cluster to belong to it, and lack the density to form their own cluster.
Figure 2 shows the 2D representation of the user-uploaded documents and their groups. The first thing we noticed and is highlighted in this figure is that the major groups are usually represented by language. Not surprisingly users tend to read content mostly on one single language.

We developed a technique to further split the groups above in smaller clusters that are semantically tighter. The final clusters can be seen in Figure 3.

After we got the clusters and subclusters shown in Figure 3, an inspection of the English subclusters was performed in order to identify their major subjects and themes. This investigation led to the incorporation of additional categories into the taxonomy, such as Philippine law, Study aids & test prep, and Teaching methods & materials, making the taxonomy broader across different content types and the browsing to this content more straightforward.
Placing documents into categories

Now that we have the taxonomy, it is time to place the documents into categories. Our approach leverages the extracted key phrases and entities discussed in part II of the series. Figure 5 illustrates how our model works: we trained a supervised model to place documents identified as text-heavy (see part I) into categories using key phrases, entities and the text.
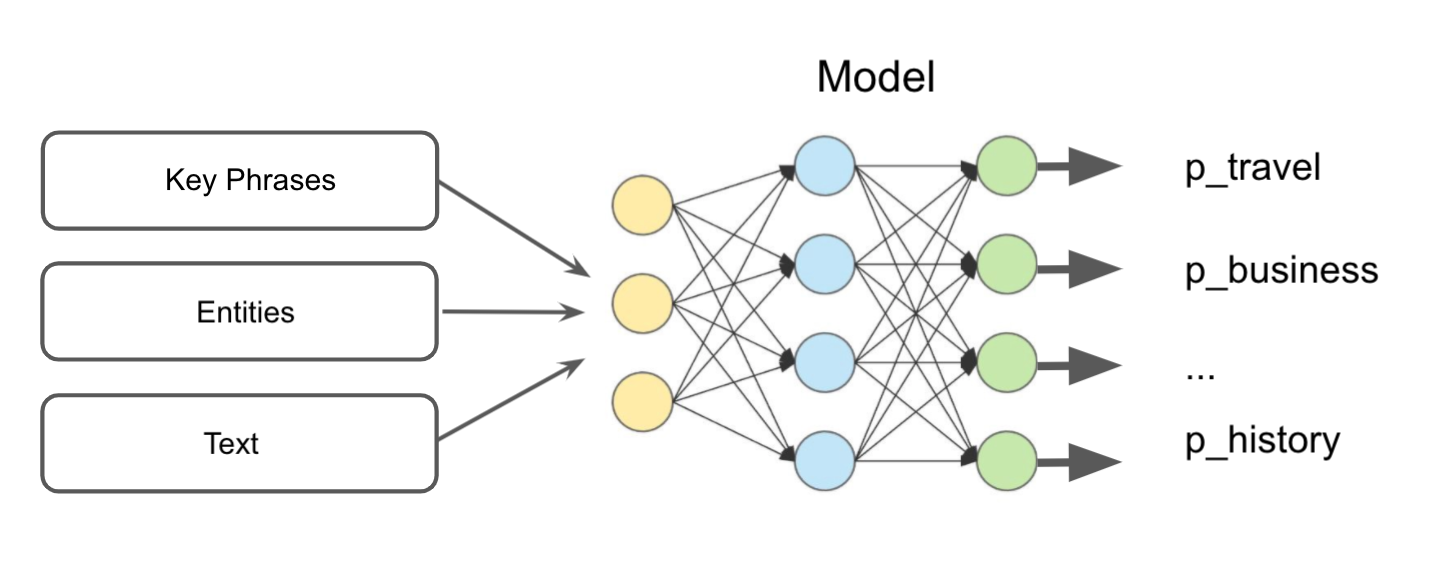
Additional insights from data
In the first iteration of the model, we had a dataset for training collected by our experts to fit the definition of each category. Not surprisingly, upon testing the model on unseen data in production, we realized that for some categories the training set was not a complete representation of the type of documents in production that could fit them. For this reason, the model was unable to generalize with the initial given training set. As an example, in the initial training set most documents about countries other than the US were documents about travel. This means that the model learned that whenever a document mentions other countries, the document is most likely about travel. For this reason, documents about business in South America, for instance, would be placed under travel by the model.
We applied a technique sometimes referred to as active learning to supplement our training set with the missing examples. Following this technique (Figure 6), the model is applied to a random sample of documents and the results analyzed by our SMEs.

This iterative process had two outcomes: improved the categories performance by re-training the model with a large variety of training example and the addition of a new category after we identified that a good fraction of documents fitted this particular category,
Additional Experiments
Throughout this project several experiments were performed to explore the full potential of the user interaction clusters. Here we will show one exciting example of such experiment.
Giving names to clusters
As explained above, in general, each subcluster shown in figure 3 is semantically tight which means that the documents belonging to a subcluster are usually about one (or few) topic(s)/subject(s).
One way to associate topics to the subclusters would require Subject Matter Experts to manually inspect the documents in each subcluster and come up with the most important topics for each of them. However, this approach is not only time consuming, and thus not scalable with new iterations of the model and a likely increasing number of clusters. It is very important to try and make this a more automatic and flexible process.
We experimented with a very promising two-step approach to automatically assign topics to subclusters. In this approach, we leverage the extracted information from the text described in part II and zero-shot topic classification (more info here):
Step 1 - Find the subclusters’ most representative key phrases by clustering their documents’ extracted info.

Step 2 - Use the result of step 1 and zero-shot topic classification to find the highest ranking topics for each subcluster.
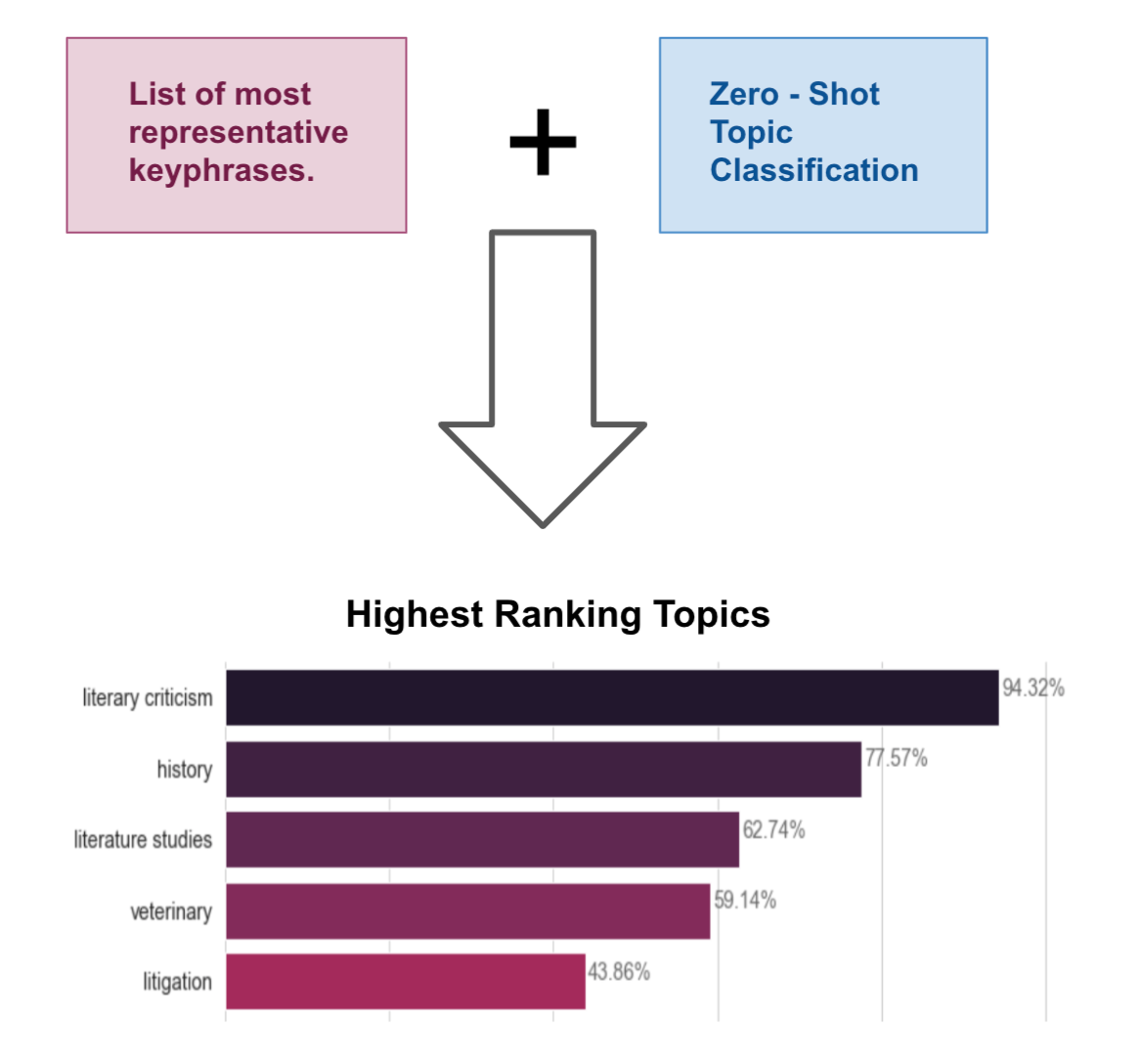
As it can be seen in figure 8, a cluster composed of literary works’ essays has as the highest ranking topic literary criticism showing the potential of this approach for automatically giving names to user interaction clusters.
Conclusion
Two important takeaways from this journey of categorizing documents were:
High quality labeled data - We found that clean and consistently labelled data was much more important to the model than hyperparameter tuning. However, getting enough documents that fit the categories in our diverse corpus was a challenge. Several techniques were used to improve model performance on unseen data. Among them, active learning proved to be an important way to collect additional training samples and to guarantee the required granularity in the training set.
Annotation alignment - High quality data and model performance are both connected to the annotation process (see more here). When multiple annotators are involved in the data collection and evaluation, alignment on the definition of each category is crucial for an accurate training and evaluation of the model. This is even more essential in text classification, since associating categories/topics to a text can be a very subjective task, specially when we are dealing with a single-label categorization problem.
This project was an important milestone in understanding our user-uploaded documents: Classifying documents has enabled users to browse documents by category from our unified taxonomy. Additionally, we now have the power of understanding the categories that each user is interested in and interacts with. Combining the user interests with business metrics could help drive innovative and unexpected product decisions as well as enrich discoverability and recommendations.
Next Steps
Improve taxonomy using a data driven approach:
Moving forward, how can we make sure that newly uploaded documents are covered in our taxonomy?
Using a data driven approach to build the taxonomy answers these questions and guarantees more flexibility, comprehensiveness, and specificity as opposed to a manually created taxonomy. As new content is uploaded to our platform and read by users, new user interaction clusters will form and help us identify recent user interests. For instance, during the pandemic, users started uploading documents related to Covid-19. Clustering the documents in 2021 for example, yields an additional cluster related to Covid-19, one that did not exist prior to the pandemic. This approach will help us build a less rigid taxonomy, a taxonomy that reflects Scribd’s vast content and is easily expandable in the long run.
Multi-language:
Now that we understand more our user-uploaded content in English and that we have a consistent pipeline to give labels to these documents, we can extend this approach to other languages
This work and post were done in collaboration with my colleague Antonia Mouawad on the Applied Research team. If you’re interested to learn more about the problems Applied Research is solving, or the systems which are built around those solutions, check out our open positions.