
Building recommendations systems like those implemented at large companies like Facebook and Pinterest can be accomplished using off the shelf tools like Elasticsearch. Many modern recommendation systems implement embedding-based retrieval, a technique that uses embeddings to represent documents, and then converts the recommendations retrieval problem into a similarity search problem in the embedding space. This post details our approach to “embedding-based retrieval” with Elasticsearch.
Context
Recommendations plays an integral part in helping users discover content that delights them on the Scribd platform, which hosts millions of premium ebooks, audiobooks, etc along with over a hundred million user uploaded items.
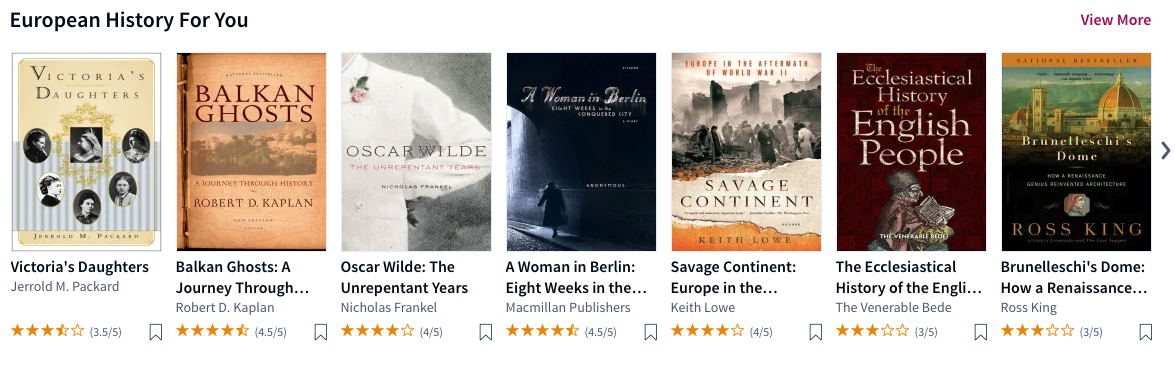
Figure One: An example of a row on Scribd’s home page that is generated by the recommendations service
Currently, Scribd uses a collaborative filtering based approach to recommend content, but this model limits our ability to personalize recommendations for each user. This is our primary motivation for rethinking the way we recommend content, and has resulted in us shifting to Transformer -based sequential recommendations. While model architecture and details won’t be discussed in this post, the key takeaway is that our implementation outputs embeddings – vector representations of items and users that capture semantic information such as the genre of an audiobook or the reading preferences of a user. Thus, the challenge is now how to utilize these millions of embeddings to serve recommendations in an online, reliable, and low-latency manner to users as they use Scribd. We built an embedding-based retrieval system to solve this use case.
Recommendations as a Faceted Search Problem
There are many technologies capable of performing fast, reliable nearest neighbors search across a large number of document vectors. However, our system has the additional challenge of requiring support for faceted search – that is, being able to retrieve the most relevant documents over a subset of the corpus defined by user-specific business rules (e.g. language of the item or geographic availability) at query time. At a high level, we desired a system capable of fulfilling the following requirements:
- The system should be able to prefilter results over one or more given facets. This facet can be defined as a filter over numerical, string, or category fields
- The system should support one or more exact distance metrics (e.g. dot product, euclidean distance)
- The system should allow updates to data without downtime
- The system should be highly available, and be able to respond to a query quickly. We targeted a service-level objective (SLO) with p95 of <100ms
- The system should have helpful monitoring and alerting capabilities, or provide support for external solutions
After evaluating several candidates for this system, we found Elasticsearch to be the most suitable for our use case. In addition to satisfying all the requirements above, it has the following benefits:
- Widely used, has a large community, and thorough documentation which allows easier long-term maintenance and onboarding
- Updating schemas can easily be automated using pre-specified templates, which makes ingesting new data and maintaining indices a breeze
- Supports custom plugin integrations
However, Elasticsearch also has some drawbacks, the most notable of which is the lack of true in-memory partial updates. This is a dealbreaker if updates to the system happen frequently and in real-time, but our use case only requires support for nightly batch updates, so this is a tradeoff we are willing to accept.
We also looked into a few other systems as potential solutions. While Open Distro for Elasticsearch (aka AWS Managed Elasticsearch) was originally considered due to its simplicity in deployment and maintenance, we decided not to move forward with this solution due to its lack of support for prefiltering. Vespa is also a promising candidate that has a bunch of additional useful features, such as true in-memory partial updates, and support for integration with TensorFlow for advanced, ML-based ranking. The reason we did not proceed with Vespa was due to maintenance concerns: deploying to multiple nodes is challenging since EKS support is lacking and documentation is sparse. Additionally, Vespa requires the entire application package containing all indices and their schemas to be deployed at once, which makes working in a distributed fashion (i.e. working with teammates and using a VCS) challenging.
How to Set Up Elasticsearch as a Faceted Search Solution
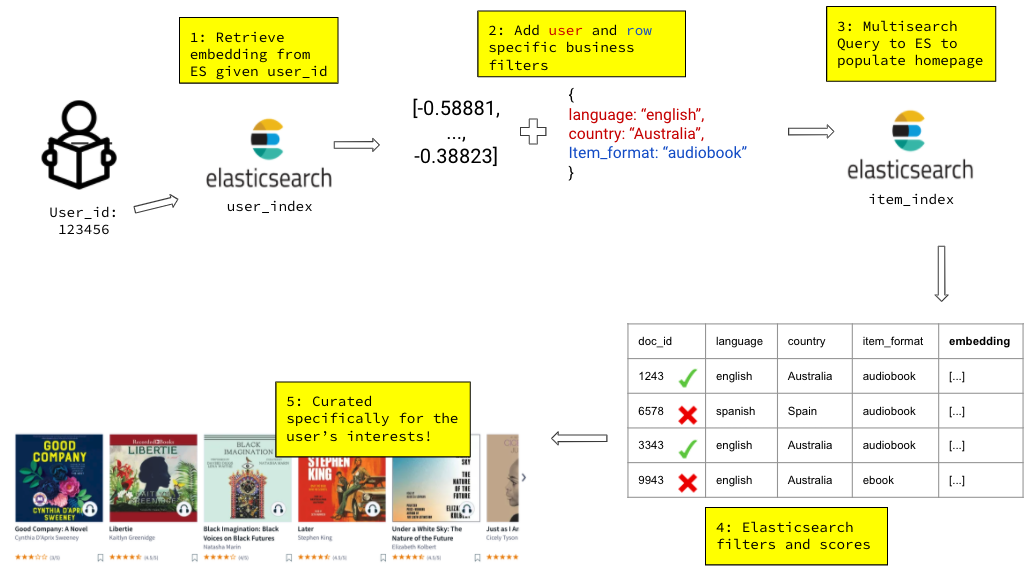
Figure Two: A high level diagram illustrating how the Elasticsearch system fetches recommendations
Elasticsearch stores data as JSON documents within indices, which are logical namespaces with data mappings and shard
configurations. For our use case, we defined two indices, a user_index and an item_index. The former is essentially
a key-value store that maps a user ID to a corresponding user embedding. A sample document in the user_index looks like:
{"_id": 4243913,
"user_embed": [-0.5888184, ..., -0.3882332]}
Notice here we use Elasticsearch’s inbuilt _id field rather than creating a custom field. This is so we can fetch user
embeddings with a GET request rather than having to search for them, like this:
curl <URL to cluster>:9200/user_index/_doc/4243913
Now that we have the user embedding, we can use it to query the item_index, which stores each item’s metadata
(which we will use to perform faceted search) and embedding. Here’s what a document in this index could look like:
{"_id": 13375,
"item_format": "audiobook",
"language": "english",
"country": "Australia",
"categories": ["comedy", "fiction", "adventure"],
"item_embed": [0.51400936,...,0.0892048]}
We want to accomplish two goals in our query: retrieving the most relevant documents to the user (which in our model corresponds to the dot product between the user and item embeddings), and ensuring that all retrieved documents have the same filter values as those requested by the user. This is where Elasticsearch shines:
curl -H 'Content-Type: application/json' \
<URL to cluster>:9200/item_index/_search \
-d \
'
{"_source": ["_id"],
"size": 30,
"query": {"script_score": {"query": {"bool":
{"must_not": {"term": {"categories": "adventure"}},
"filter": [{"term": {"language": "english"}},
{"term": {"country": "Australia"}}]}},
"script": {"source": "double value = dotProduct(params.user_embed, 'item_embed');
return Math.max(0, value+10000);",
"params": {"user_embed": [-0.5888184, ..., -0.3882332]}}}}}
'
Let’s break this query down to understand what’s going on:
- Line 2: Here we are querying the
item_indexusing Elasticsearch’s_searchAPI - Lines 5,6: We specify which attributes of the item documents we’d like returned (in this case, only
_id), and how many results (30) - Line 7: Here we are querying using the
script_scorefeature; this is what allows us to first prefilter our corpus and then rank the remaining subset using a custom script - Lines 8-10: Elasticsearch has various different boolean query types for filtering. In this example we specify that we
are interested only in
englishitems that can be viewed inAustraliaand which are not categorized asadventure - Lines 11-12: Here is where we get to define our custom script. Elasticsearch has a built-in
dot_productmethod we can employ, which is optimized to speed up computation. Note that our embeddings are not normalized, and Elasticsearch prohibits negative scores. For this reason, we had to include the score transformation in line 12 to ensure our scores were positive - Line 13: Here we can add parameters which are passed to the scoring script
This query will retrieve recommendations based on one set of filters. However, in addition to user filters, each row on
Scribd’s homepage also has row-specific filters (for example, the row “Audiobooks Recommended for You” would have a
row-specific filter of "item_format": "audiobook"). Rather than making multiple queries to the Elasticsearch cluster
with each combination of user and row filters, we can conduct multiple independent searches in a single query using the
_msearch API. The following example query generates recommendations for hypothetical “Audiobooks Recommended for You”
and “Comedy Titles Recommended for You” rows:
curl -H 'Content-Type: application/json' \
<URL to cluster>:9200/_msearch \
-d \
'
{"index": "item_index"}
{"_source": ["_id"],
"size": 30,
"query": {"script_score": {"query": {"bool":
{"must_not": {"term": {"categories": "adventure"}},
"filter": [{"term": {"language": "english"}},
{"term": {"item_format": "audiobook"}},
{"term": {"country": "Australia"}}]}},
"script": {"source": "double value = dotProduct(params.user_embed, 'item_embed');
return Math.max(0, value+10000);",
"params": {"user_embed": [-0.5888184, ..., -0.3882332]}}}}}
{"index": "item_index"}
{"_source": ["_id"],
"size": 30,
"query": {"script_score": {"query": {"bool":
{"must_not": {"term": {"categories": "adventure"}},
"filter": [{"term": {"language": "english"}},
{"term": {"categories": "comedy"}},
{"term": {"country": "Australia"}}]}},
"script": {"source": "double value = dotProduct(params.user_embed, 'item_embed');
return Math.max(0, value+10000);",
"params": {"user_embed": [-0.5888184, ..., -0.3882332]}}}}}
'
Shard Configuration
Elasticsearch stores multiple copies of data across multiple nodes for resilience and increased query performance in a process known as sharding. The number of primary and replica shards is configurable only at index creation time. Here are some things to consider regarding shards:
- Try out various shard configurations to see what works best for each use case. Elastic recommends 20-40GB of data per shard, while eBay likes to keep their shard size below 30GB. However, these values did not work for us, and we found much smaller shard sizes (<5GB) to boost performance in the form of reduced latency at query time.
- When updating data, do not update documents within the existing index. Instead, create a new index, ingest updated documents into this index, and re-alias from the old index to the new one. This process will allow you to retain older data in case an update needs to be reverted, and allows re-configurability of shards at update time.
Cluster Configuration
We deployed our cluster across multiple data and primary nodes to enjoy the benefits of data redundancy, increased availability, and the ability to scale horizontally as our service grows. We found that deploying the cluster across multiple availability zones results in an increased latency during query time, but this is a tradeoff we accepted in the interest of availability.
As for hardware specifics, we use AWS EC2 instances to host our cluster. In production, we have 3 t3a.small primary-only
nodes, 3 c5d.12xlarge data nodes, and 1 t3.micro Kibana node. The primary-only nodes are utilized only in a coordinating
role (to route requests, distribute bulk indexing, etc), essentially acting as smart load balancers. This is why these
nodes are much smaller than the data nodes, which handle the bulk of storage and computational costs. Kibana is a data
visualization and monitoring tool; however, in production we use Datadog for our monitoring and alerting responsibilities,
which is why we do not allocate many resources for the Kibana node.
What Generating Recommendations Looks Like
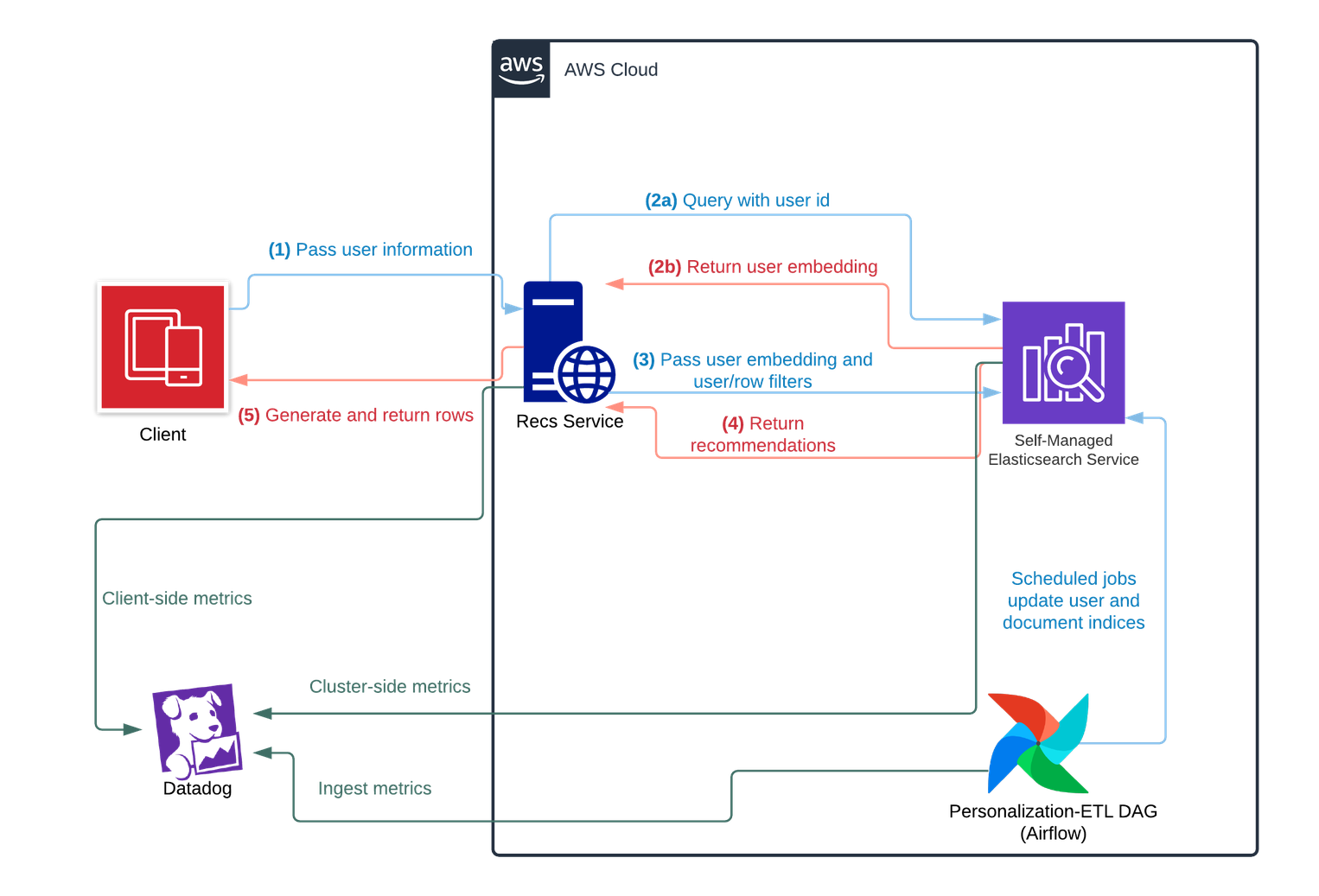
Figure Three: a diagram illustrating the system design for Personalization’s Embedding-based Retrieval Service
Step by step, this is how recommendations are generated for a user when he/she requests the home page:
- The Scribd app passes the user’s information to the recommendations service
- The recommendations service queries Elasticsearch with the user’s ID to retrieve their user embedding, which is stored in a user index
- The recommendations service once again queries Elasticsearch, this time with the user’s embedding along with their user query filters. This query is a multi-search request to the item index: one for every desired row
- Elasticsearch returns these recommendations to the service, which are postprocessed and generated into rows before being sent to the client
- The client renders these recommendations and displays them to the user
With this approach, Elasticsearch will serve two purposes: acting as a key-value store, and retrieving recommendations. Elasticsearch is, of course, a slower key-value store than traditional databases, but we found the increase in latency to be insignificant (~5ms) for our use case. Furthermore, the benefit of this approach is that it only requires maintaining data in one system; using multiple systems to store data would create a consistency challenge.
The underlying Personalization model is very large, making retraining it a very expensive process. Thus, it needs to be retrained often enough to account for factors like user preference drift but not too often so as to be efficient with computational resources. We found retraining the model weekly worked well for us. item embeddings, which typically update only incrementally, are also recomputed weekly. However, user embeddings are recomputed daily to provide fresh recommendations based on changing user interests. These embeddings along with relevant metadata are ingested into the Elasticsearch index in a batch process using Apache Spark and are scheduled through Apache Airflow. We monitor this ingest process along with real-time serving metrics through Datadog.
Load Testing
Our primary goal during load testing was to ensure that our system was able to reliably respond to a “reasonably large” number of requests per second and deliver a sufficient number of relevant recommendations, even under the confines of multiple facets within each query. We also took this opportunity to experiment with various aspects of our system to understand their impact on performance. These include:
- Shard and replica configuration: We found that increasing the number of shards increased performance, but only to a point; If a cluster is over-sharded, the overhead of each shard outweighs the marginal performance gain of the additional partition
- Dataset size: We artificially increased the size of our corpus several times to ensure the system’s performance would remain sufficient even as our catalog continues to grow
- Filter and mapping configurations: Some filters (like
rangeinequalities) are more expensive than traditional categorical filters. Additionally, increasing the number of fields in each document also has a negative impact on latency. Our use case calls for several filters across hundreds of document fields, so we played with several document and query configuration to find the one most optimal for the performance of our system
Our system is currently deployed to production and serves ~50rps with a p95 latency <60ms.
Results
Using Scribd’s internal A/B testing platform, we conducted an experiment comparing the existing recommendations service with the new personalization model with embedding-based retrieval architecture across the home and discover page surfaces. The test ran for approximately a month with >1M Scribd users (trialers or subscribers) assigned as participants. After careful analysis of results, we saw the following statistically significant (p<0.01) improvements in the personalization variant compared to the control experience:
- Increase in the number of users who clicked on a recommended item
- Increase in the average number of clicks per user
- Increase in the number of users with a read time of at least 10 minutes (in a three day window)
These increases represent significant business impact on key performance metrics. The personalization model currently generates recommendations for every (signed in) Scribd user’s home and discover pages.
Next Steps
Now that the infrastructure and model are in place, we are looking to add a slew of improvements to the existing system. Our immediate efforts will focus on expanding the scope of this system to include more surfaces and row modules within the Scribd experience. Additional long term projects include the addition of an online contextual reranker to increase the relevance and freshness of recommendations and potentially integrating our system with an infrastructure as code tool to more easily manage and scale compute resources.
Thank you for reading! We hope you found this post useful and informative.
Thank You 🌮
Thank you to Snehal Mistry, Jeffrey Nguyen, Natalie Medvedchuk, Dimitri Theoharatos, Adrian Lienhard, and countless others, all of whom provided invaluable guidance and assistance throughout this project.
(giving tacos 🌮 is how we show appreciation here at Scribd)