Jekyll2024-02-26T21:01:57+00:00https://tech.scribd.com/feed.xmlScribd TechnologyScribd technology builds and delivers one of the world's largest libraries, bringing the best books, audiobooks, and journalism to millions of people around the world.The Evolution of the Machine Learning Platform2024-02-05T00:00:00+00:002024-02-05T00:00:00+00:00https://tech.scribd.com/blog/2024/evolution-of-mlplatformMachine Learning Platforms (ML Platforms) have the potential to be a key component in achieving production ML at scale without large technical debt, yet ML Platforms are not often understood. This document outlines the key concepts and paradigm shifts that led to the conceptualization of ML Platforms in an effort to increase an understanding of these platforms and how they can best be applied.
Technical Debt and development velocity defined
Development Velocity
Machine learning development velocity refers to the speed and efficiency at which machine learning (ML) projects progress from the initial concept to deployment in a production environment. It encompasses the entire lifecycle of a machine learning project, from data collection and preprocessing to model training, evaluation, validation deployment and testing for new models or for re-training, validation and deployment of existing models.
Technical Debt
The term “technical debt” in software engineering was coined by Ward Cunningham, Cunningham used the metaphor of financial debt to describe the trade-off between implementing a quick and dirty solution to meet immediate needs (similar to taking on financial debt for short-term gain) versus taking the time to do it properly with a more sustainable and maintainable solution (akin to avoiding financial debt but requiring more upfront investment). Just as financial debt accumulates interest over time, technical debt can accumulate and make future development more difficult and expensive.
The idea behind technical debt is to highlight the consequences of prioritizing short-term gains over long-term maintainability and the need to address and pay off this “debt” through proper refactoring and improvements. The term has since become widely adopted in the software development community to describe the accrued cost of deferred work on a software project.
Technical Debt in Machine Learning
Originally a software engineering concept, Technical debt is also relevant to Machine Learning Systems infact the landmark google paper suggest that ML systems have the propensity to easily gain this technical debt.
Machine learning offers a fantastically powerful toolkit for building useful complex prediction systems quickly. This paper argues it is dangerous to think of these quick wins as coming for free. Using the software engineering framework of technical debt , we find it is common to incur massive ongoing maintenance costs in real-world ML systems
As the machine learning (ML) community continues to accumulate years of experience with livesystems, a wide-spread and uncomfortable trend has emerged: developing and deploying ML sys-tems is relatively fast and cheap, but maintaining them over time is difficult and expensive
Technical debt is important to consider especially when trying to move fast. Moving fast is easy, moving fast without acquiring technical debt is alot more complicated.
The Evolution Of ML Platforms
DevOps – The paradigm shift that led the way
DevOps is a methodology in software development which advocates for teams owning the entire software development lifecycle. This paradigm shift from fragmented teams to end-to-end ownership enhances collaboration and accelerates delivery. Dev ops has become standard practice in modern software development and the adoption of DevOps has been widespread, with many organizations considering it an essential part of their software development and delivery processes. Some of the principles of DevOps are:
Automation
Continuous Testing
Continuous Monitoring
Collaboration and Communication
Version Control
Feedback Loops
Platforms – Reducing Cognitive Load
This shift to DevOps and teams teams owning the entire development lifecycle introduces a new challenge—additional cognitive load. Cognitive load can be defined as
The total amount of mental effort a team uses to understand, operate and maintain their designated systems or tasks.
The weight of the additional load introduced in DevOps of teams owning the entire software development lifecycle can hinder productivity, prompting organizations to seek solutions.
Platforms emerged as a strategic solution, delicately abstracting unnecessary details of the development lifecycle. This abstraction allows engineers to focus on critical tasks, mitigating cognitive load and fostering a more streamlined workflow.
The purpose of a platform team is to enable stream-aligned teams to deliver work with substantial autonomy. The stream-aligned team maintains full ownership of building, running, and fixing their application in production. The platform team provides internal services to reduce the cognitive load that would be required from stream-aligned teams to develop these underlying services.
Infrastructure Platform teams enable organisations to scale delivery by solving common product and non-functional requirements with resilient solutions. This allows other teams to focus on building their own things and releasing value for their users
ML Ops – Reducing technical debt of machine learning
The ability of ML systems to rapidly accumulate technical debt has given rise to the concept of MLOps. MLOps is a methodology that takes inspiration from and incorporates best practices of the DevOps, tailoring them to address the distinctive challenges inherent in machine learning. MLOps applies the established principles of DevOps to machine learning, recognizing that merely a fraction of real-world ML systems comprises the actual ML code. Serving as a crucial bridge between development and the ongoing intricacies of maintaining ML systems.
MLOps is a methodology that provides a collection of concepts and workflows designed to promote efficiency, collaboration, and sustainability of the ML Lifecycle. Correctly applied MLOps can play a pivotal role controlling technical debt and ensuring the efficiency, reliability, and scalability of the machine learning lifecycle over time.
Scribd’s ML Platform – MLOps and Platforms in Action
At Scribd we have developed a machine learning platform which provides a curated developer experience for machine learning developers. This platform has been built with MLOps in mind which can be seen through its use of common DevOps principles.
Automation:
Applying CI/CD strategies to model deployments through the use of Jenkins pipelines which deploy models from the Model Registry to AWS based endpoints.
Automating Model training throug the use of Airflow DAGS and allowing these DAGS to trigger the deployment pipelines to deploy a model once re-training has occured.
ContinuousTesting:
Applying continuous testing as part of a model deployment pipeline, removing the need for manual testing.
Increased tooling to support model validation testing.
Monitoring:
Monitoring real time inference endpoints
Monitoring training DAGS
Monitoring batch jobs
Collaboration and Communication:
Feature Store which provides feature discovery and re-use
Model Database which provides model collaboration
Version Control:
Applying version control to experiments, machine learning models and features
]]>Ben ShawData and AI Summit Wrap-up2022-07-21T00:00:00+00:002022-07-21T00:00:00+00:00https://tech.scribd.com/blog/2022/data-ai-summit-videosWe brought a whole team to San Francisco to present and attend this year’s Data and
AI Summit, and it was a blast!
I
would consider the event a success both in the attendance to the Scribd hosted
talks and the number of talks which discussed patterns we have adopted in our
own data and ML platform.
The three talks I wrote about
previously were well received and have
since been posted to YouTube along with hundreds of other talks.
QP Hou, Scribd Emeritus, presented on
his foundational work to ensure correctness within delta-rs during his session:
R Tyler Croy co-presented with Gavin
Edgley from Databricks on the cost analysis work Scribd has done to efficiently
grow our data platform with:
Members of the Scribd team participated in a panel to discuss the past,
present, and future of Delta Lake on the expo floor. We also took advantage of
the time to have multiple discussions with our colleagues at Databricks about
their product and engineering roadmap, and where we can work together to
improve the future of Delta Lake, Unity catalog, and more.
For those working in the data, ML, or infrastructure space, there are a lot of
great talks available online from the event, which I highly recommend
checking out. Data and AI Summit is a great event for leaders in the industry
to get together, so we’ll definitely be back next year!
]]>R Tyler CroyAccelerating Looker with Databricks SQL Serverless2022-06-28T00:00:00+00:002022-06-28T00:00:00+00:00https://tech.scribd.com/blog/2022/databricks-serverlessWe recently migrated Looker to a Databricks SQL Serverless, improving our
infrastructure cost and reducing the footprint of infrastructure we need to
worry about! “Databricks SQL” which provides a single load balanced Warehouse
for executing Spark SQL queries across multiple Spark clusters behind the
scenes. “Serverless” is an evolution of that concept, rather than running a SQL
Warehouse in our AWS infrastructure, the entirety of execution happens on the
Databricks side. With a much simpler and faster interface, queries executed in
Looker now return results much faster to our users than ever before!
When we originally provisioned our “Databricks SQL” warehouses, we worked
together with our colleagues at Databricks to ensure the terraform provider
for Databricks is
ready for production usage, which as of today is Generally Available. That
original foundation in Terraform allowed us to more easily adopt SQL Serverless
once it was made available to us.
The feature was literally brand new so there were a few integration hurdles we
had to work through with our colleagues at Databricks, but we got things up and
running in short order. By adopting SQL Serverless, we could avoid setting up
special networking, IAM roles, and other resources within our own AWS account,
we can instead rely on pre-provisioned compute resources within Databricks’ own
infrastructure. No more headache of ensuring all of the required infra is in
place and setup correctly!
The switch to Serverless reduced our infra configuration and management
footprint, which by itself is an improvement. We also noticed a significant
reduction in cold start times for the SQL Serverless Warehouse compared to the
standard SQL Warehouse. The faster start-up times meant we could configure even
lower auto-terminate times on the warehouse, savings us even more on
unproductive and idle cluster costs.
On the Looker side there really wasn’t any difference in the connection
configuration other than a URL change. In the end, after some preparation work
a simple 5 minute change in Looker, and a simple 5 minute change in Terraform
switched everything over to Databricks SQL Serverless, and we were ready to
rock! Our BI team is very happy with the performance, especially on cold start
queries. Our CFO is happy about reducing infrastructure costs. And I’m happy
about simpler infrastructure!
]]>Hamilton HordScribd is presenting at Data and AI Summit 20222022-04-28T00:00:00+00:002022-04-28T00:00:00+00:00https://tech.scribd.com/blog/2022/data-ai-summit-2022We are very excited to be presenting and attending this year’s Data and AI
Summit which will be
hosted virtually and physically in San Francisco from June 27th-30th.
Throughout the course of 2021 we completed a number of really interesting
projects built around delta-rs and the
Databricks platform which we are thrilled to share with a broader audience.
In addition to the presentations listed below, a number of Scribd engineers who
are responsible for data and ML platform, machine learning systems, and more,
will be in attendance if you want to meet up and learn more about how Scribd
uses data and ML to change the way the world reads!
There are so many great sessions to watch in person or online during the event,
particularly around Delta Lake, which is one of our
favorite technologies and powers our entire data platform. We are also
expecting some great ML related talks as data and ML begin to overlap more and
more. We hope to see you there!
]]>R Tyler CroyArmadillo makes audio players in Android easy2021-09-29T00:00:00+00:002021-09-29T00:00:00+00:00https://tech.scribd.com/blog/2021/android-audio-player-tutorial-with-armadilloArmadillo is the fully featured audio player library Scribd uses to play and
download all of its audiobooks and podcasts, which is now open
source. It specializes in playing HLS
or MP3 content that is broken down into chapters or tracks. It leverages
Google’s Exoplayer library for its audio engine. Exoplayer wraps a variety of
low level audio and video apis but has few opinions of its own for actually
using audio in an Android app.
The leap required from Exoplayer to audio player
is enormous both in terms of the amount of code needed as well as the amount of
domain knowledge required about complex audio related subjects. Armadillo
provides a turn-key solution for powering an audio player and providing the
information to update a UI.
Easy-to-use because it outputs state updates with everything needed for a UI or analytics. Works in the background state.
Effective because it uses Google’s Exoplayer as the playback engine.
Ready-to-go out of the box usage for a developer looking to use an audio player.
Robust because it contains numerous configuration options for supporting most any requirement and includes a number of other android apis
required for a high quality audio player.
What does it include?
Support for HLS and MP3 audio
Exoplayer for downloading and playback
MediaBrowserService so the app can be played in the background, browsed by other apps, and integrated with Android Auto.
MediaSession to support commands from media controllers, ex. a bluetooth headset.
Getting Started:
The library is hosted with Github packages so you will need to add the Github registry with authentication to your build.gradle file. See the official docs on authenticating here. But you will need to:
It is as easy as adding this code snippet to your Activity / Fragment to play your first piece of content.
// construct your mediavalmedia=AudioPlayable(id=0,title="Google Hosted Mp3",request=AudioPlayable.MediaRequest.createHttpUri("https://storage.googleapis.com/exoplayer-test-media-0/play.mp3"),chapters=emptyList())// initialize the playervalarmadilloPlayer=ArmadilloPlayerFactory.init()// begin playbackarmadilloPlayer.beginPlayback(media)// listen for state updatesarmadilloPlayer.armadilloStateObservable.subscribe{// update your UI here}
That’s all you need to get started!
Next Steps:
For a more complex example, please see the TestApp included in the library. If
you have any problems, don’t be afraid to open up an issue on
GitHub.
]]>Nathan SassCategorizing user-uploaded documents2021-07-28T00:00:00+00:002021-07-28T00:00:00+00:00https://tech.scribd.com/blog/2021/categorizing-user-uploaded-documentsScribd offers a variety of publisher and user-uploaded content to our users and
while the publisher content is rich in metadata, user-uploaded content
typically is not. Documents uploaded by the users have varied subjects and
content types which can make it challenging to link them together. One way to
connect content can be through a taxonomy - an important type of structured
information widely used in various domains. In this series, we have already
shared how we identify document
types and extract information
from documents, this post
will discuss how insights from data were used to help build the taxonomy and
our approach to assign categories to the user-uploaded documents.
Building the taxonomy
The unified taxonomy is a tree-structure with two layers that was designed by combining our Subject Matter Experts’ (SME) knowledge of the book industry subject headings (BISAC categories) and data-driven insights. We used user-reading patterns to find topics that could help enrich our unified taxonomy.
Data-Driven Insights
Users have been interacting with Scribd content for more than 10 years, building reading patterns throughout time. We leveraged these reading patterns to create dense vector representations of documents similarly to word2vec in text.
Figure 1: Schematic representation of our approach: reading sequences are used to create vector representations for user uploaded documents. The vector dimension shown is merely illustrative.
For this work we focused only on user uploaded documents and on one type of interaction (reading for a minimum amount of time). The embeddings dimensions (and other hyperparamenters) were chosen to optimize the hit-ratio@20 (Caselles-Dupré, et al 2018) increasing how semantically tight the embeddings are.
Now that we have the embeddings we would like to use them to find groups of documents with similar subjects and topics. Finding these groups will help us identify categories that should be added to the taxonomy.
Dimensionality reduction allows for dense clusters of documents to be found more efficiently and accurately in the reduced space in comparison to the original high-dimensional space of our embeddings. We reduced the dimension of the embeddings using the t-SNE algorithm. t-SNE has a non-linear approach that can capture the smaller relationships between the points, as well as the global structure of the data. We used an implementation of t-SNE (Fast Fourier Transform accelerated Interpolation-based t-SNE” - FIt-SNE) that is flexible and does not sacrifice accuracy for speed.
Finally, we grouped the user-uploaded docs by clustering the reduced embeddings using HDBSCAN. HDBSCAN separates data points into clusters based on the density distribution. It also has a feature to detect noise, which are points that are too far from the nearest detected cluster to belong to it, and lack the density to form their own cluster.
Figure 2 shows the 2D representation of the user-uploaded documents and their groups. The first thing we noticed and is highlighted in this figure is that the major groups are usually represented by language. Not surprisingly users tend to read content mostly on one single language.
Figure 2: Initial 2D representation of the embeddings using t-SNE and HDBSCAN. Each colored group represents a cluster found by HDBSCAN. Spread grey points were identified as noise.
We developed a technique to further split the groups above in smaller clusters that are semantically tighter. The final clusters can be seen in Figure 3.
Figure 3: Final 2D representation of the embeddings after further splitting of each cluster. Each colored group represents a subcluster found by HDBSCAN for a particular cluster. Spread grey points were identified as noise.
After we got the clusters and subclusters shown in Figure 3, an inspection of the English subclusters was performed in order to identify their major subjects and themes. This investigation led to the incorporation of additional categories into the taxonomy, such as Philippine law, Study aids & test prep, and Teaching methods & materials, making the taxonomy broader across different content types and the browsing to this content more straightforward.
Placing documents into categories
Figure 4: Diagram of Scribd’s multi-component pipeline. Categorization is one of the downstream tasks highlighted in the diagram.
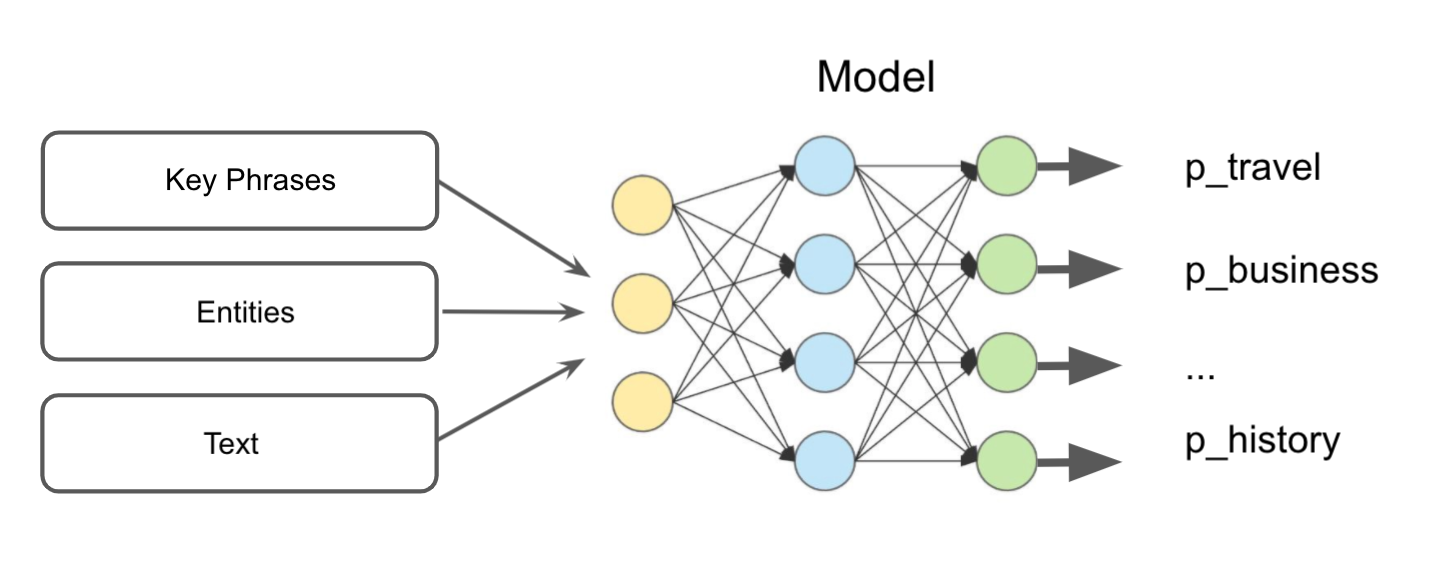
Now that we have the taxonomy, it is time to place the documents into categories. Our approach leverages the extracted key phrases and entities discussed in part II of the series. Figure 5 illustrates how our model works: we trained a supervised model to place documents identified as text-heavy (see part I) into categories using key phrases, entities and the text.
Figure 5: Model architecture to categorize docs.
Additional insights from data
In the first iteration of the model, we had a dataset for training collected by our experts to fit the definition of each category. Not surprisingly, upon testing the model on unseen data in production, we realized that for some categories the training set was not a complete representation of the type of documents in production that could fit them. For this reason, the model was unable to generalize with the initial given training set. As an example, in the initial training set most documents about countries other than the US were documents about travel. This means that the model learned that whenever a document mentions other countries, the document is most likely about travel. For this reason, documents about business in South America, for instance, would be placed under travel by the model.
We applied a technique sometimes referred to as active learning to supplement our training set with the missing examples. Following this technique (Figure 6), the model is applied to a random sample of documents and the results analyzed by our SMEs.
Figure 6: Active Learning Process used to improve model performance.
This iterative process had two outcomes: improved the categories performance by re-training the model with a large variety of training example and the addition of a new category after we identified that a good fraction of documents fitted this particular category,
Additional Experiments
Throughout this project several experiments were performed to explore the full potential of the user interaction clusters. Here we will show one exciting example of such experiment.
Giving names to clusters
As explained above, in general, each subcluster shown in figure 3 is semantically tight which means that the documents belonging to a subcluster are usually about one (or few) topic(s)/subject(s).
One way to associate topics to the subclusters would require Subject Matter Experts to manually inspect the documents in each subcluster and come up with the most important topics for each of them. However, this approach is not only time consuming, and thus not scalable with new iterations of the model and a likely increasing number of clusters. It is very important to try and make this a more automatic and flexible process.
We experimented with a very promising two-step approach to automatically assign topics to subclusters. In this approach, we leverage the extracted information from the text described in part II and zero-shot topic classification (more info here):
Step 1 - Find the subclusters’ most representative key phrases by clustering their documents’ extracted info.
Figure 7: Illustration of Step 1.
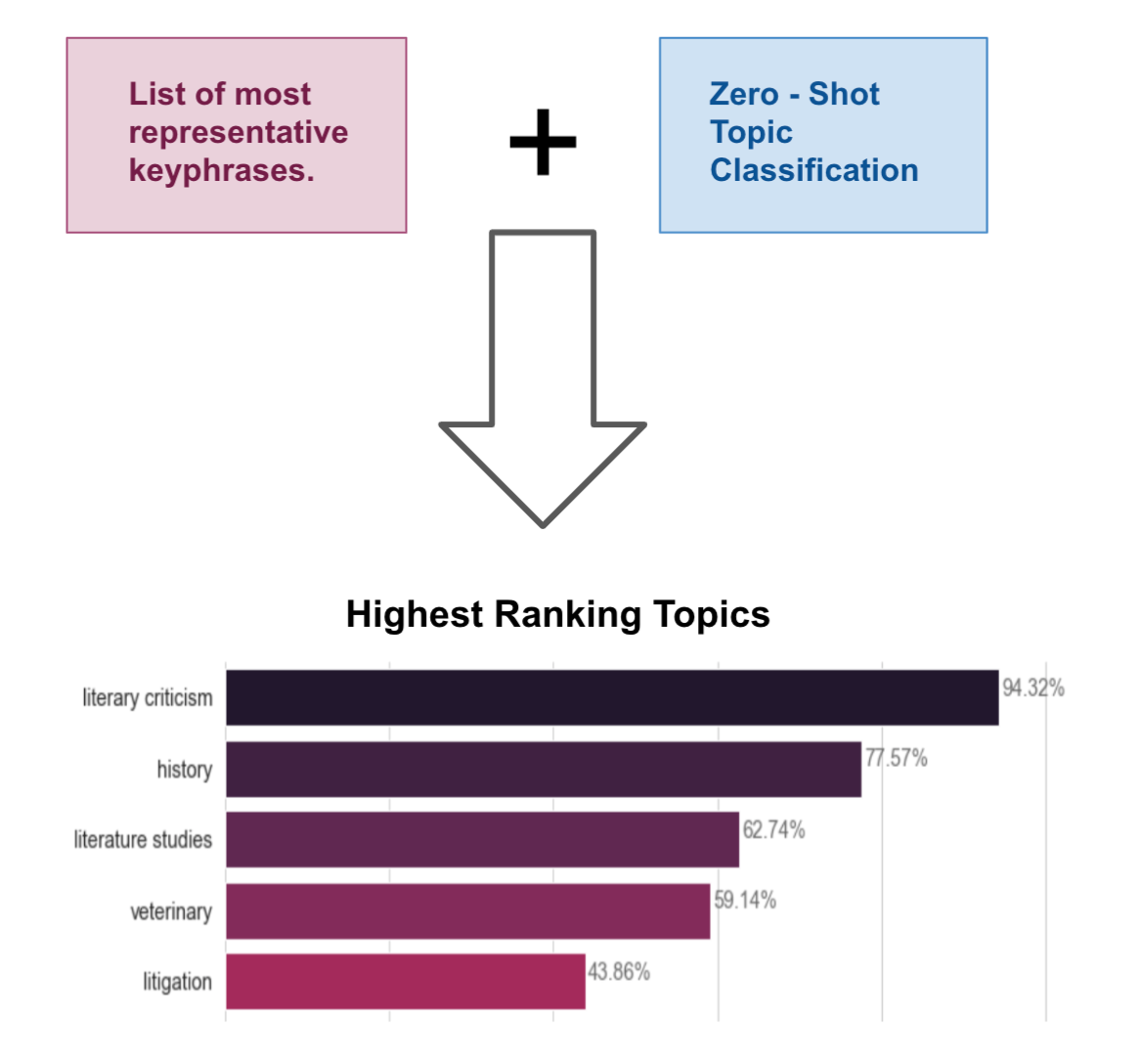
Step 2 - Use the result of step 1 and zero-shot topic classification to find the highest ranking topics for each subcluster.
Figure 8: Illustration of Step 2. The bar plot with the highest ranking topics is the result of this approach for a subcluster that contains essays about several literary works.
As it can be seen in figure 8, a cluster composed of literary works’ essays has as the highest ranking topic literary criticism showing the potential of this approach for automatically giving names to user interaction clusters.
Conclusion
Two important takeaways from this journey of categorizing documents were:
High quality labeled data - We found that clean and consistently labelled data was much more important to the model than hyperparameter tuning. However, getting enough documents that fit the categories in our diverse corpus was a challenge. Several techniques were used to improve model performance on unseen data. Among them, active learning proved to be an important way to collect additional training samples and to guarantee the required granularity in the training set.
Annotation alignment - High quality data and model performance are both connected to the annotation process (see more here). When multiple annotators are involved in the data collection and evaluation, alignment on the definition of each category is crucial for an accurate training and evaluation of the model. This is even more essential in text classification, since associating categories/topics to a text can be a very subjective task, specially when we are dealing with a single-label categorization problem.
This project was an important milestone in understanding our user-uploaded documents: Classifying documents has enabled users to browse documents by category from our unified taxonomy. Additionally, we now have the power of understanding the categories that each user is interested in and interacts with. Combining the user interests with business metrics could help drive innovative and unexpected product decisions as well as enrich discoverability and recommendations.
Next Steps
Improve taxonomy using a data driven approach:
Moving forward, how can we make sure that newly uploaded documents are covered in our taxonomy?
Using a data driven approach to build the taxonomy answers these questions and guarantees more flexibility, comprehensiveness, and specificity as opposed to a manually created taxonomy. As new content is uploaded to our platform and read by users, new user interaction clusters will form and help us identify recent user interests. For instance, during the pandemic, users started uploading documents related to Covid-19. Clustering the documents in 2021 for example, yields an additional cluster related to Covid-19, one that did not exist prior to the pandemic. This approach will help us build a less rigid taxonomy, a taxonomy that reflects Scribd’s vast content and is easily expandable in the long run.
Multi-language:
Now that we understand more our user-uploaded content in English and that we have a consistent pipeline to give labels to these documents, we can extend this approach to other languages
This work and post were done in collaboration with my colleague Antonia Mouawad on the Applied Research team. If you’re interested to learn more about the problems Applied Research is solving, or the systems which are built around those solutions, check out our open positions.
]]>Monique Alves CruzInformation Extraction at Scribd2021-07-21T00:00:00+00:002021-07-21T00:00:00+00:00https://tech.scribd.com/blog/2021/information-extraction-at-scribdExtracting metadata from our documents is an important part of our discovery
and recommendation pipeline, but discerning useful and relevant details
from text-heavy user-uploaded documents can be challenging. This is
part 2 in a series of blog posts describing a multi-component machine learning
system the Applied Research team built to extract metadata from our documents in order to enrich downstream discovery models. In this post, we present the challenges and
limitations the team faced when building information extraction NLP models for Scribd’s
text-heavy documents and how they were solved.
As mentioned in part 1, we now have a way of identifying text-heavy documents. Having done that, we want to build dedicated models to deepen our semantic understanding of them. We do this by extracting keyphrases and entities.
Figure 1: Diagram of our multi-component machine learning system.
Keyphrases are phrases that represent major themes/topics, whereas entities are proper nouns such as people, places and organizations. For example, when a user uploads a document about the Manhattan project, we will first detect it is text-heavy, then extract keyphrases and entities. Potential keyphrases would be “atomic bomb” and “nuclear weapons” and potential entities would be “Robert Oppenheimer” and “Los Alamos”.
As keyphrase extraction brings out the general topics discussed in a document, it helps put a cap on the amount of information kept per document, resulting in a somewhat uniform representation of documents irrespective of their original size. Entity extraction, on the other hand, identifies elements in a text that aren’t necessarily reflected by keyphrases only. We found the combination of keyphrase and entity extraction to provide a rich semantic description of each document.
The rest of this post will explain how we approached keyphrase and entity extraction, and how we identified whether a subset of these keyphrases and entities are present in a knowledge base (also known as linking), and introduce how we use them to categorize documents.
Keyphrase Extraction
Typically a keyphrase extraction system operates in two steps as indicated in this survey:
Using heuristics to extract a list of words/phrases that serve as candidate keyphrases, such as part-of-speech language patterns, stopwords filtering, and n-grams with Wikipedia article titles
Determining which of these candidate keyphrases are most likely to be keyphrases, using one of the two approaches:
Supervised approaches such as binary classification of candidates (useful/not useful), structural features based on positional encoding, etc.
Unsupervised approaches such as selecting terms with the highest tf-idf and clustering.
Training a decent supervised model to be able to extract keyphrases across a wide variety of topics would require a large amount of training data, and might generalize very poorly. For this reason, we decided to take the unsupervised approach.
Our implementation of keyphrase extraction is optimized for speed without sacrificing keyphrase quality much. We employ both a statistical method and language specific rules to identify them efficiently.
We simply start by filtering out stopwords and extracting the n-grams with a base n (bi-grams in our case, n=2). This step is fast and straightforward and results in an initial set of candidate n-grams.
Limiting the results to a single n-gram class, however, results in split keyphrases, which makes linking them to a knowledge base a challenging task. For that, we attempt to agglomerate lower order n-grams into potentially longer keyphrases, as long as they occur at a predetermined minimum frequency as compared to the shorter n-gram, based on the following a pattern:
A sequence of nouns (NN) possibly interleaved with either Coordinating Conjunctions (CC) or Prepositions and Subordinating Conjunctions (IN).
Here are a few examples:
Assuming the minimum frequency of agglomeration is 0.5, that means we would only replace the bi-gram world (NN) health (NN) by world (NN) health (NN) organization (NN) as long as world health organization occurs at least 50% as much as world health occurs.
Replace Human (NNP) Development (NNP) with Center(NNP) for (IN) Global (NNP) Development (NNP) only if the latter occurs at least a predetermined percentage of time as compared to the former.
This method results in more coherent and complete keyphrases that could be linked more accurately to a knowledge base entry.
Finally we use the count of occurrences of the candidate keyphrase as a proxy to its importance. This method is reliable for longer documents, as the repetition of a keyphrase tends to reliably indicate its centrality to the document’s topic.
Named Entities
Keyphrases are only one side of finding what’s important in a document. To further capture what a document is about, we must also consider the named entities that are present.
Named Entity Extraction systems identify instances of named entities in a text, which we can count in order to represent their importance in the document, similar to how we did with keyphrases.
Naively counting named entities through exact string matches surfaces an interesting problem: a single entity may go by many names or aliases, which means string frequency is an unreliable measurement of importance. In the example given in Figure 2, we know that “MIll”, “John Stuart Mill” and “Stuart Mill” all refer to the same person. This means that Mill is even more central to the document than the table indicates, since he is referred to a total of 8 times instead of 5.
Figure 2: Excerpt from John Stuart Mill’s Wikipedia page (left) and Top 5 Named Entity counts of the first few paragraphs (right).
To address this counting problem, let’s introduce a few abstractions:
Named Entity refers to a unique person, place or organization. Because of their uniqueness, we can represent them with a unique identifier (ID).
Named Entity Alias (or simply Alias), is one of possibly many names associated with a particular entity.
Canonical Alias is the preferred name for an entity.
Named Entity Mention (or simply Mention), refers to each occurrence in a text that a Named Entity was referred to, regardless of which Alias was used.
Knowledge Base is a collection of entities, allowing us to query for ID, canonical name, aliases and other information that might be relevant for the task at hand. One example is Wikidata.
The first step to solve the counting problem is to normalize the names a document uses to refer to a named entity. Using our abstractions, this means we want to find all the mentions in a document, and use its alias to find the named entity it belongs to. Then, replace it with either the canonical name or the named entity ID - this distinction will become clearer later on.
Entity Normalization
Given a set of aliases that appear in a document, we developed heuristics (e.g. common tokens, initials) to identify which subset of aliases refer to the same named entity. This allowed us to limit our search space when comparing aliases.
Using our previous example to illustrate this method, we start by assuming the canonical alias is the longest alias in a text for a given entity, and attempt to merge aliases together by evaluating which aliases match the heuristics we developed.
Table 1: Top 5 occurring aliases in the first few paragraphs of John Stuart Mill’s Wikipedia page, some referring to the same person.
Comparing entities with each other using exact token matching as a heuristic would solve this:
Table 2: Pairwise alias comparisons and resulting merges. Matches highlighted in bold.
By replacing all mentions with its corresponding canonical alias, we are able to find the correct named entity counts.
One edge case is when an alias might refer to more than one entity: e.g. the alias “Potter” could refer to the named entities “Harry Potter” or “James Potter” within the Harry Potter universe. To solve this, we built an Entity Linker, which determines which named entity is the most likely to match the alias given the context. This process is further explained in the Linking to a Knowledge Base section.
When an entity is not present in a knowledge base, we cannot use Named Entity Linking to disambiguate. In this case, our solution uses a fallback method that assigns the ambiguous mention (Potter) to the closest occurring unambiguous mention that matches the heuristics (e.g. Harry).
Linking to a Knowledge Base
Given that many keyphrases and entities mentioned in a document are notable, they are likely present in a knowledge base. This allows us to leverage extra information present in the knowledge base to improve the normalization step as well as downstream tasks.
Being able to embed entities in the same space as text is useful, as this unlocks the ability to compare possible matching named entity IDs with the context in which they’re mentioned, and make a decision on whether an alias we’re considering might be one of the entities in the knowledge base (in which case we will use IDs), or whether the alias doesn’t match any entity in the knowledge base, in which case we fall back to using the assumed canonical alias.
At Scribd we make use of Entity Linking to not only improve the Entity Normalization step, but also to take advantage of entity and keyphrase embeddings as supplemental features.
Discussion
Putting all of this together, we can:
Link documents to keyphrases and entities
Find the relative importance of each in a document
Take advantage of relevant information in knowledge bases
This has enabled some interesting projects:
In one of them, the Applied Research team built a graph of documents along with their related keyphrases and entities. Embedding documents, keyphrases and entities in the same space allowed us to discover documents by analogy. For example, take The Count of Monte Cristo by Alexandre Dumas, a 19th century French novel about revenge. If we add to its embedding the embedding of science_fiction, it leads us to a collection of science fiction novels by Jules Verne (another 19th century French author), such as 20,000 Leagues Under the Sea and Journey to the Center of the Earth.
Keyphrase extractions have also been useful in adding clarity to document clusters. By extracting the most common keyphrases of a cluster, we can derive a common theme for the cluster’s content:
Figure 3: Top keyphrases in a document cluster. The keywords imply that the documents therein are related to dentistry & healthcare, which was confirmed by manually inspecting the documents.
In yet another project, the team leveraged precomputed knowledge base embeddings to represent a document in space through a composition of the entities and keyphrases it contains. These features allowed us to understand the documents uploaded by our users and improve the content discovery on the platform.
To see how we use the information extracted to classify documents into a
taxonomy, make sure to check out part 3.
If you’re interested to learn more about the problems Applied Research
is solving, or the systems which are built around those solutions,
check out our open positions!
]]>Antonia MouawadPresenting Rust and Python Support for Delta Lake2021-07-20T00:00:00+00:002021-07-20T00:00:00+00:00https://tech.scribd.com/blog/2021/growing-delta-ecosystem-with-rustDelta Lake is integral to our data platform which is why we have invested
heavily in delta-rs to support our
non-JVM Delta Lake needs. This year I had the opportunity to share the progress
of delta-rs at Data and AI Summit. Delta-rs was originally started by my colleague QP just over a year ago and it has now grown to now a multi-company project with numerous contributors, and downstream projects such as kafka-delta-ingest.
In the session embedded below, I introduce the delta-rs project which is
helping bring the power of Delta Lake outside of the Spark ecosystem. By
providing a foundational Delta Lake library in Rust, delta-rs can enable native
bindings in Python, Ruby, Golang, and more.We will review what functionality
delta-rs supports in its current Rust and Python APIs and the upcoming roadmap.
I also try to give an overview of one of the first projects to use it in
production:
kafka-delta-ingest, which
builds on delta-rs to provide a high throughput service to bring data from
Kafka into Delta Lake.
Investing in data platform tools and automation is a key part of the vision for
Platform Engineering which encompasses Data Engineering, Data Operations, and
Core Platform. We have a number of open positions
at the moment including a position to work closely with me as Data Engineering
Manager.
The leader of the Data Engineering team will help deliver data tools and
solutions for internal customers building on top of Delta Lake, Databricks,
Airflow, and Kafka. Suffice it to say, there’s a lot of really interesting work
to be done!
]]>R Tyler CroyIdentifying Document Types at Scribd2021-07-12T00:00:00+00:002021-07-12T00:00:00+00:00https://tech.scribd.com/blog/2021/identifying-document-typesUser-uploaded documents have been a core component of Scribd’s business from
the very beginning, understanding what is actually in the document corpus
unlocks exciting new opportunities for discovery and recommendation.
With Scribd anybody can upload and share
documents, analogous to YouTube and videos. Over
the years, our document corpus has become larger and more diverse which has
made understanding it an ever-increasing challenge.
Over the past year one of the missions of the Applied Research team has been to
extract key document metadata to enrich
downstream discovery systems. Our approach combines semantic understanding with
user behaviour in a multi-component machine learning system.
This is part 1 in a series of blog posts explaining the challenges and
solutions explored while building this system. This post presents the
limitations, challenges, and solutions encountered when developing a model to
classify arbitrary user-uploaded documents.
Initial Constraints
The document corpus at Scribd stretches far and wide in terms of content, language and structure. An arbitrary document can be anything from math homework to Philippine law to engineering schematics. In the first stage of the document understanding system, we want to exploit visual cues in the documents. Any model used here must be language-agnostic to apply to arbitrary documents. This is analogous to a “first glance” from humans, where we can quickly distinguish a comic book from a business report without having to read any text. To satisfy these requirements, we use a computer vision model to predict the document type. But what is a “type”?
Identifying Document Types
A necessary question to ask, but a difficult one to answer – what kind of documents do we have? As mentioned in the section above, we’re interested in differentiating documents based on visual cues, such as text-heavy versus spreadsheet versus comics. We’re not yet interested in more granular information like fiction VS non-fiction.
Our approach to this challenge was twofold. Firstly, talking to subject matter experts at Scribd on the kinds of documents they have seen in the corpus. This was and continues to be very informative, as they have domain-specific knowledge that we leverage with machine learning. The second solution was to use a data-driven method to explore documents. This consisted of creating embeddings for documents based on their usage. Clustering and plotting these embeddings on an interactive map allowed us to examine document structure in different clusters. Combining these two methods drove the definition of document types. Below is an example of one of these maps we used to explore the corpus.
Figure 1: Map of the document corpus built from user-interaction embeddings. More on this method in a future post.
We converged on 6 document types, which included sheet-music, text-heavy, comics and tables. More importantly, these 6 classes don’t account for every single document in our corpus. While there are many different ways of dealing with out-of-distribution examples in the literature, our approach explicitly added an “other” class to the model and train it. We talk more about its intuition, potential solutions to the problem and challenges faced in the coming sections.
Document Classification
As mentioned in the introduction, we need an approach that is language and content agnostic, meaning that the same model will be appropriate for all documents, whether they contain images, text, or a combination of both. To satisfy these constraints we use a computer vision model to classify individual pages. These predictions can then be combined with other meta-data such as page count or word count to form a prediction for the entire document.
Gathering Labelled Pages and Documents
Before the model training started, we faced an interesting data gathering problem. Our goal is to classify documents, so we must gather labelled documents. However, in order to train the page classifier mentioned above, we must also gather labelled pages. Naively, it might seem appropriate to gather labelled documents and use the document label for each of its pages. This isn’t appropriate as a single document can contain multiple types of pages. As an example, consider the pages in this document.
Figure 2: Three different pages from the same document to demonstrate why we can't take the document label and assign it to each page.
The first and third pages can be considered text-heavy, but definitely not the second. Taking all the pages of this document and labelling them as text-heavy would severely pollute our training and testing data. The same logic applies to each of our 6 classes.
To circumvent this challenge, we took an active learning approach to data gathering. We started with a small set of hand-labelled pages for each class and trained binary classifiers iteratively. The binary classification problem is simpler than the multi-class problem, requiring less hand-labelled data to obtain reliable results. At each iteration, we evaluated the most confident and least confident predictions of the model to get a sense of its inductive biases. Judging from these, we supplemented the training data for the next iteration to tweak the inductive biases and have confidence in the resulting model and labels. The sheet music class is a prime example of tweaking inductive biases. Below is an example of a page that can cause a sheet music misclassification if the model learns that sheet music is any page with horizontal lines. Supplementing the training data at each iteration helps get rid of inductive biases like this.
Figure 3: Example of possible sheet music misclassification due to wrong inductive biases.
After creating these binary classifiers for each class, we have a large set of reliable labels and classifiers that can be used to gather more data if necessary.
Building a Page Classifier
The page classification problem is very similar to ImageNet classification, so we can leverage pre-trained ImageNet models. We used transfer learning in fast.ai and PyTorch to fine-tune pre-trained computer vision architectures for the page-classifier. After initial experiments, it was clear that models with very high ImageNet accuracy, such as EfficientNet, did not perform much better on our dataset. While it’s difficult to pinpoint exactly why this is the case, we believe it is because of the nature of the classification task, the page resolutions and our data.
We found SqueezeNet, a relatively established lightweight architecture, to be the best balance between accuracy and inference time. Because models such as ResNets and DenseNets are so large, they take a lot of time to train and iterate on. However, SqueezeNet is an order of magnitude smaller than these models, which opens up more possibilities in our training scheme. Now we can train the entire model and are not limited to using the pre-trained architecture as a feature-extractor, which is the case for larger models.
Figure 4: SqueezeNet architectures taken from the paper. Left: SqueezeNet; Middle: SqueezeNet with simple bypass; Right: SqueezeNet with complex bypass.
Additionally, for this particular model, low inference time is key in order to run it on hundreds of millions of documents. Inference time is also directly tied to costs, so an optimal cost/benefit ratio would require significantly higher performance to justify higher processing time.
Ensembled Pages for Document Classification
We now have a model to classify document pages and need to use them to determine a prediction for documents and want to combine these classifications with additional meta-data, such as total page count, page dimensions, etc. However, our experiments here showed that a simple ensemble of the page classifications provided an extremely strong baseline that was difficult to beat with meta-data.
To increase efficiency, we sample 4 pages from the document to ensemble. This way we don’t run into processing issues for documents with thousands of pages. This was chosen based on the performance of the classifier and the page distribution in the document corpus, which empirically verified our assumption that this sample size reasonable represents each document.
Error Analysis and Overconfidence
After error analysis of a large sample of documents from production, we found that some classes were returning overconfident but wrong predictions. This is a very interesting challenge and one that has seen an explosion of academic research recently. To elaborate, we found documents that were predicted wrongly with over 99% confidence scores. A major consequence of this is that it negates the effectiveness of setting a threshold on model output in order to increase precision.
While there are different ways of dealing with this, our approach involved two steps. Firstly, we utilized the “other” class mentioned earlier. By adding many of these adversarial, out-of-distribution examples to the “other” class and re-training the model, we were able to quickly improve metrics without changing model architecture. Secondly, this affected some classes more than others. For these, individual binary classifiers were built to improve precision.
Where do we go from here?
Figure 5: Diagram of the overall document understanding system. The red box is what we talked about in this post
Now that we have a model to filter documents based on visual cues, we can build dedicated information extraction models for each document type – sheet music, text-heavy, comics, tables. This is exactly how we proceed from here, and we start with extracting information from text-heavy documents.
Part 2 in this series will dive deeper into the challenges and solutions our
team encountered while building these models. If you’re interested to learn more about the problems Applied Research is solving or the systems which are built around those solutions, check out our open positions!
]]>Jonathan RamkissoonAutomating Databricks with Terraform2021-07-08T00:00:00+00:002021-07-08T00:00:00+00:00https://tech.scribd.com/blog/2021/automate-databricks-with-terraformThe long term success of our data platform relies on putting tools into the
hands of developers and data scientists to “choose their own adventure”. A big
part of that story has been Databricks which we
recently integrated with Terraform to make it easy to
scale a top-notch developer experience. At the 2021 Data and AI Summit, Core
Platform infrastructure engineer Hamilton
Hord and Databricks engineer Serge
Smertin presented on the Databricks terraform provider
and how it’s been used by Scribd.
In the session embedded below, they share the details on the Databricks (Labs)
Terraform
integration
and how it can automate literally every aspect required for a production-grade
platform: data security, permissions, continuous deployment and so on. They
also discuss the ways in which our Core Platform team enables internal
customers without acting as gatekeepers for data platform changes. Just about
anything they might need in Databricks is a pull request away!
In hindsight, it’s mind-boggling how much manual configuration we had to
previously maintain. With the Terraform provider for Databricks we can very
easily test, reproduce, and audit hundreds of different business critical
Databricks resources. Coupling Terraform with the recent “multi-workspace”
support that Databricks unveiled in 2020 means we can also now provision an
entirely new environment in a few hours!
Investing in data platform tools and automation is a key part of the vision for
Platform Engineering which encompasses Data Engineering, Data Operations, and
Core Platform. We have a number of open positions
at the moment, but I wanted to call special attention to the Data Engineering
Manager
role for which we’re currently hiring. The leader of the Data Engineering team
will help deliver data tools and solutions for internal customers building on
top of Delta Lake, Databricks, Airflow, and Kafka. Suffice it to say, there’s a
lot of really interesting work to be done!