What is A/B testing?
](https://cdn-images-1.medium.com/max/2000/1*sPjoc8Z3NskxSgkTkohvPw.png)
As data scientists, we trust in the power of statistics. One of our roles at Scribd is to help the product, design and engineering teams leverage that power to improve our service. A/B testing is a useful tool to leverage this power to uncover causal relationship between product changes and business metrics. The statistical methods are straightforward, and the range of applications are diverse.
A/B testing is important because in some cases, external factors like day of the week or traffic inflow can have a greater impact on business metrics than specific product changes. Randomly assigning users in A/B tests ensures external factors do not bias each variant. The benefits of this process is why A/B testing is a crucial part of how we make decisions at Scribd.
What do we A/B test at Scribd?
We started A/B testing at Scribd so that we could confidently measure the impact of changes to three areas of the business: growth, recommendations, and search. We’ve since expanded this to include every product initiative, as we find that stress-testing our hypothesis against real world data is invaluable.
Growth
Optimizing the growth funnel is an excellent application for A/B testing. Each step of the pipeline can be quantified and improved: new users -> sign-ups -> free trials -> subscribers.
Recommendations
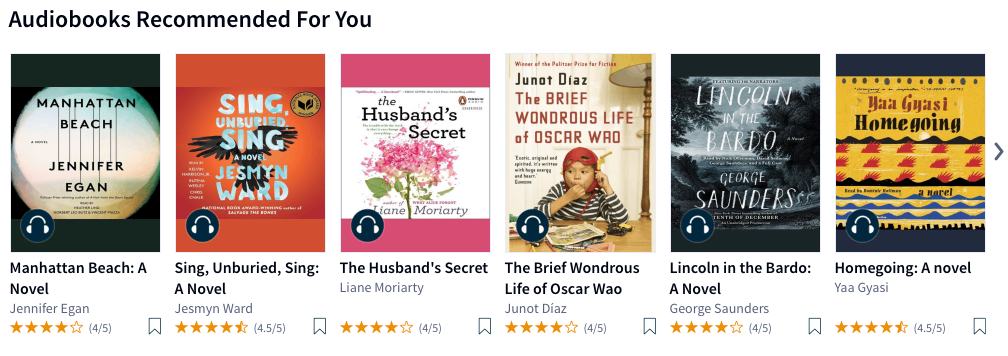
We have A/B tested front-end changes, ranking algorithms, module sorting algorithms and various different recommender algorithms.
Search
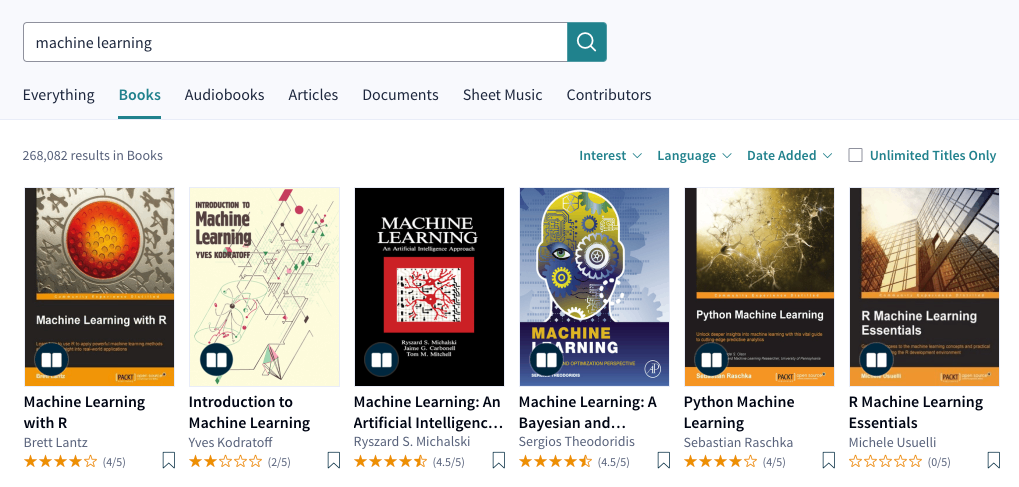
Search A/B tests include using a seq2seq model for query parsing, as well as various algorithms that determine how we return and rank search results. We continue to experiment with models that incorporate user feedback into the rankings.
Building a framework
Assigning users to A/B tests
Properly handling a/b test assignment across platforms is a complex problem that requires walking through all the specific scenarios in detail.
When we first started A/B testing there needed to be a system for assigning users to a test. The test assignment system had to provide a consistent experience whether or not the user was logged-in. If a user had multiple devices, all devices must receive the same experience; if a device was associated with multiple users, all users must receive the same experience. We built an assignment system that could be used across mobile and web platforms and handle hundreds of millions of users per test. The assignment system was the starting point and foundation on which we built everything else.
Metrics
](https://cdn-images-1.medium.com/max/2000/1*rFB0iO6xdcrZ_Uv9GHJKEQ.png) http://dilbert.com/strip/2014-03-08
http://dilbert.com/strip/2014-03-08
Our test metrics have evolved from product driven ad-hoc metrics to well-defined metrics that are correlated with retention. At first, there was no shared system for analyzing A/B tests; every analysis consisted of ad-hoc queries.
To automate this, we built out a pipeline that tracks the four main types of primary business metrics: sign-ups, retention, engagement, and financial results. Each type of primary metric contains between 5 and 20 metrics. Not every metric applies to every test but having a shared system reduces analysis time and increases the visibility of effects in a given test.
Before launching a test the product manager and data scientist agree on a decision framework that specifies the quantitative results required before moving forward with a test variant. To simplify the decision-making process, we predetermine a hierarchy of metrics in order of importance to the business. For example, metrics are weighted higher if the test increases retention or subscriptions than if it increases reading.
Building out a pipeline that tracks all primary business metrics for every test increased the data team’s productivity, reducing the average time to analyze a test and write up a report from 5 days to 2 days.
The next phase of the A/B test framework will be adding secondary metric tracking to provide visibility into how users are interacting with each new feature. The goal is to understand better why a specific product change increased or decreased a primary metric. There are two secondary metric projects on our roadmap:
-
Web and mobile event tracking to allow stakeholders to select and monitor specific events of interest like CTAs or promotional banners.
-
Highly granular recommendation and search metric dashboards to improve our understanding of how user activity increased or decreased.
Estimating the days to run a test
](https://cdn-images-1.medium.com/max/2000/1*T5fyOS-Qx9iw2kcZ5PZklQ.png)
There are trade-offs in every business A/B test. A/B testing needs to fit in with the business model and can’t become a bottleneck for product development. It’s important to be able to provide an answer to “how long does this test need to run?”
While there is no such thing as a statistically significant sample, we can provide the number of days to run a test given four conditions: desired effect size, sample size, significance level, and statistical power. An example of this is as follows: the test requires 100,000 samples per variant given that we want to detect a 2% change, with a 5% significance level (5% false positive rate), and 80% statistical power (20% false negative rate), if an average of 10,000 users are assigned to the test a day we can estimate the test needs to run for 10 days.
To automate test runtime estimations we built a Tableau dashboard that has adjustable parameters for effect size, significance level, and statistical power and accounts for the number of variants in the test. Given these inputs, it visualizes the number of samples required and the number of days left before we can analyze the test.
Estimating test runtime works well in a business context; the data scientist can determine runtime factors before running the test ensuring the test runtime will fit into the product development pipeline. If it’s essential to detect a small change, then it’s necessary to run the test longer or collect a larger sample. Automating the test runtime estimations reduces the work required from the data team to make an estimate from hours to minutes.
Visualizations & Reports
Automating A/B calculations and visualizations has been a high ROI initiative.
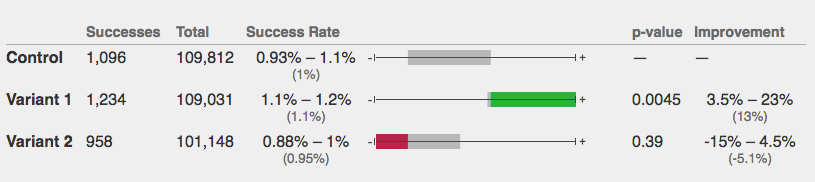 Abba calculator
Abba calculator
The data team started off using online calculators for A/B test analyses. The Abba calculator from Thumbtack worked great for proportion metrics with 2 or more variants. A/B test calculators can be sufficient, but there are a few limitations: manually inputting data is time-consuming, ad-hoc calculations lack transparency, and online calculators have limitations like not being able to calculate mean metrics for multiple variant tests.
The highest impact projects have been building a Tableau A/B test dashboard and a Python A/B test package. The Tableau dashboard plots confidence intervals for all primary metrics and allows the data team to quickly copy the relevant primary metrics to a report. All the user data can be filtered by features like country, language, and device.
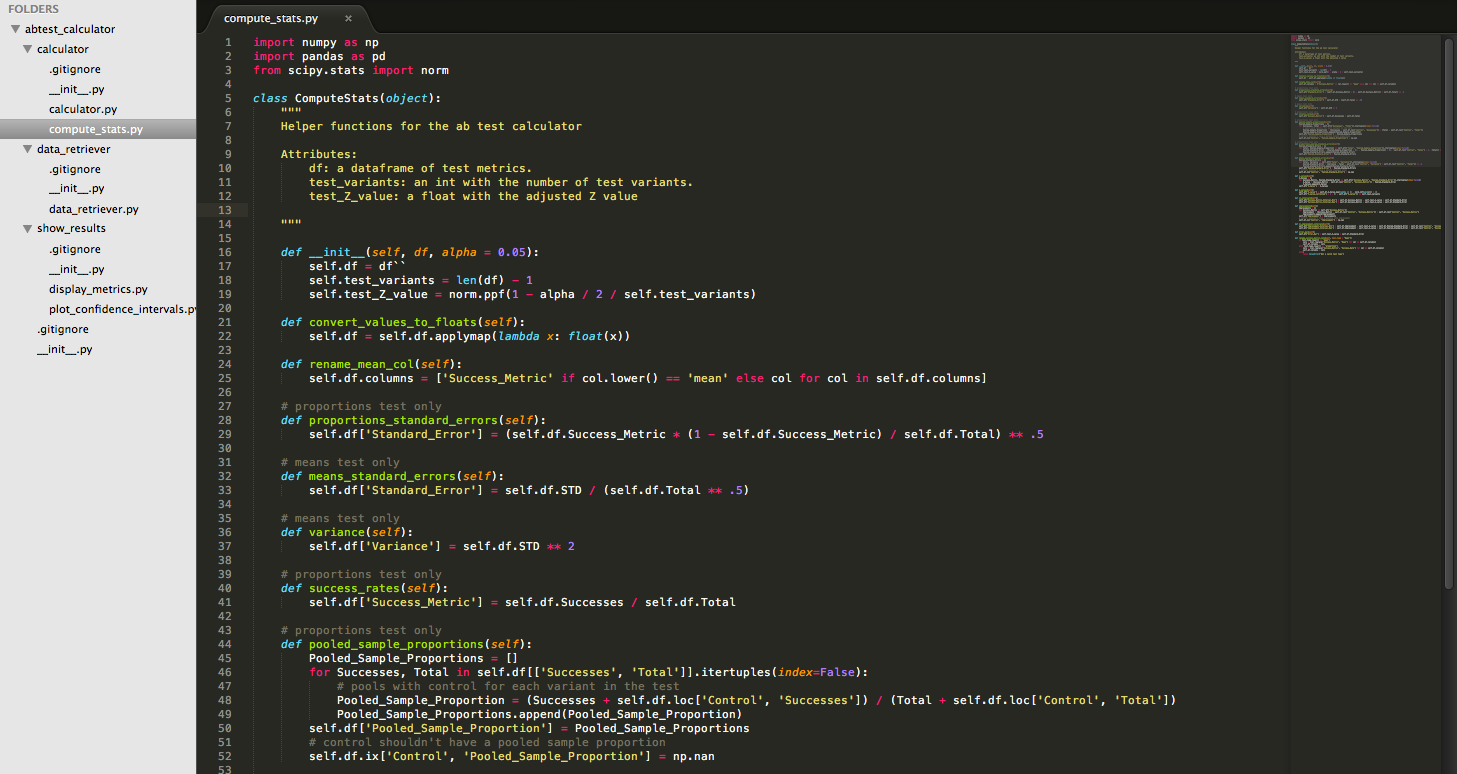 Python A/B test calculator package
Python A/B test calculator package
 Jupyter Notebook — Python A/B test calculator
Jupyter Notebook — Python A/B test calculator
The Python A/B test package handles the manual work of calculating ad-hoc metrics. The package has 3 main methods: retrieving the data from Hive, calculating the test statistics, and plotting confidence intervals. We’ve found that working in Jupyter notebooks and pushing to the data team git repository reduces duplicate work and adds transparency.
Conclusion
We use A/B testing as a methodology, in the sense that we can benefit from constantly testing our hypothesis against outcomes to determine causation (or at least get close to it). It’s not necessarily about a single A/B test, which may be a false positive/negative despite following all of the best practices of setting an appropriate power, p-value, effect size, and randomization. The value comes from the culture of putting our product instinct, qualitative research efforts and design process to the metal to see how users actually respond and interact with new versions of the product.