We love A/B testing at Scribd. What follows is a specific example to give you an inside look at the process from idea to implementation for an algorithm test.
We’ll cover how we optimized our home page, transitioned from hard-coded rules to a multi-armed bandit, and increased reads from recommendations by 10%. If you want to help us make it even better, come join us.

The product problem
Guessing which recommendation rows people like is probably a bad idea
Users have diverse tastes. This bears repeating. Users have diverse tastes. I cannot understate the complexity of user preferences in a system that includes books, audiobooks, magazines and user-generated content. We need a system that automatically optimizes which rows to show various groups of users. And while we had a good idea of how well each row performed before implementing the multi-armed bandit, the row position biased the row type’s performance. Position bias, both horizontal and vertical, makes evaluating a recommendation system’s effectiveness challenging, since it’s one of the biggest determinants of interaction.
There are too many combinations of rows to AB test
The home page has 42 possible row types, which we can display in 10 row positions, resulting in 5*10¹⁵ potential combinations = 42! / (42 -10)! To give you some context, this is more stars than the entire Milky Way galaxy has!
The diversity of rows are important
If diversity weren’t a factor, one reasonable solution would be to randomly display every row type until there was enough unbiased data to rank the rows. But given that the diversity and order of rows are essential, we needed a more sophisticated method.
The scale of the product opportunity
The homepage is a primary destination for users, so even a small improvement makes a big impact.
Before we dive into our approach to fix this, let’s take a step back and look at how we got here.
A brief history of the home page at Scribd
Version 1: 100% hand-picked rows on the home page. Row types and row positions were hard coded.
Yes, everyone needs a version 1 that you can cringe at over beers.
Version 2: A mix of personalized rows and editorially created rows. Row types and row positions were hard coded.
We evolved in our sophistication to create a better user experience.
Version 3: A mix of personalized rows and editorially created rows. The multi-armed bandit determines row types and row positions.
Our latest effort at combining user interaction and our recommendations system to deliver the best possible experience.
 Version 3
Version 3
Our solution: Multi-armed bandits
A multi-armed bandit is an efficient way to find the optimal policy given many possible actions. One common example is a gambler choosing between various slot machines, each with an unknown expected payout. The gambler’s goal is to maximize their payout by deciding which slot machines to play and how many times to play each one. Each slot machine is an “arm” and the gambler is the “multi-armed bandit”. As the multi-armed bandit receives feedback about which arms have the highest expected payout, they increase their proportion of trials with the higher expected payout arms. The goal is to balance choosing the highest expected payout “exploitation” with receiving sufficient information “exploration” and find the arm with the highest expected payout.
Ranked bandit algorithm
Choosing which recommendation rows to show is an ideal problem for a multi-armed bandit. There are 42 possible recommendation row types “Recommended for you”, “Best Selling”, etc. and the goal is to show the rows with the highest expected interaction value (clicks, reading, etc).
As an added layer of complexity, want to control for the rows that perform the best given all the rows placed above it. We can learn rankings that take neighboring rows into account by using one multi-armed bandit for each row position.
[Learning Diverse Rankings with Multi-Armed Bandits](https://pdfs.semanticscholar.org/5675/7c983518b0604d54719df85fcd0adf789044.pdf)
Implementation of the ranked bandit algorithm
We split our users into 3 groups based on their site activity.
There’s one multi-armed bandit per group and row position on the home page. *30 multi-armed bandits in total = 10 row positions * 3 groups. *Each multi-armed bandit has 42 arms, one for each row type.
When a row type is interacted with, we increase that arm’s value. To calculate the score, we divide that value by the total number of row views.
To find an optimal ranking, the multi-armed bandit needs to balance exploitation with exploration.
, [lecture 11](http://ai.berkeley.edu/slides/Lecture%2011%20--%20Reinforcement%20Learning%20II/SP14%20CS188%20Lecture%2011%20--%20Reinforcement%20Learning%20II.pptx).*](https://cdn-images-1.medium.com/max/2784/1*j-TYe1Bd7My-gdt64zp_cg.png) Image source: UC Berkeley AI course slide, lecture 11.
Image source: UC Berkeley AI course slide, lecture 11.
-
Exploitation — shows rows that have the highest estimated score.
-
Exploration — boosts rows that have fewer views.
Calculating an arm’s score and exploration bonus:
-
1000 views on all rows
-
100 views for the “Best Selling” row
-
5 clicks for the “Best Selling” row
-
2 reads for the “Best Selling” row
The boosted value for the “Best Selling” row is:
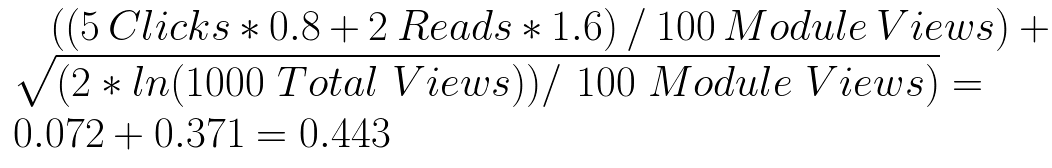
The multi-armed bandit shows the row with the highest score + bonus. If a row type doesn’t apply to a user it shows the next highest ranked row. For example, if the “Library” row ranks first but they have nothing saved to their library they will receive a row with content, such as “Similar to”.
At first, the multi-armed bandits show random rows, but within a week the multi-armed bandit started exploiting the highest scoring rows by showing them in higher positions.
The multi-armed bandit learning scores for row types
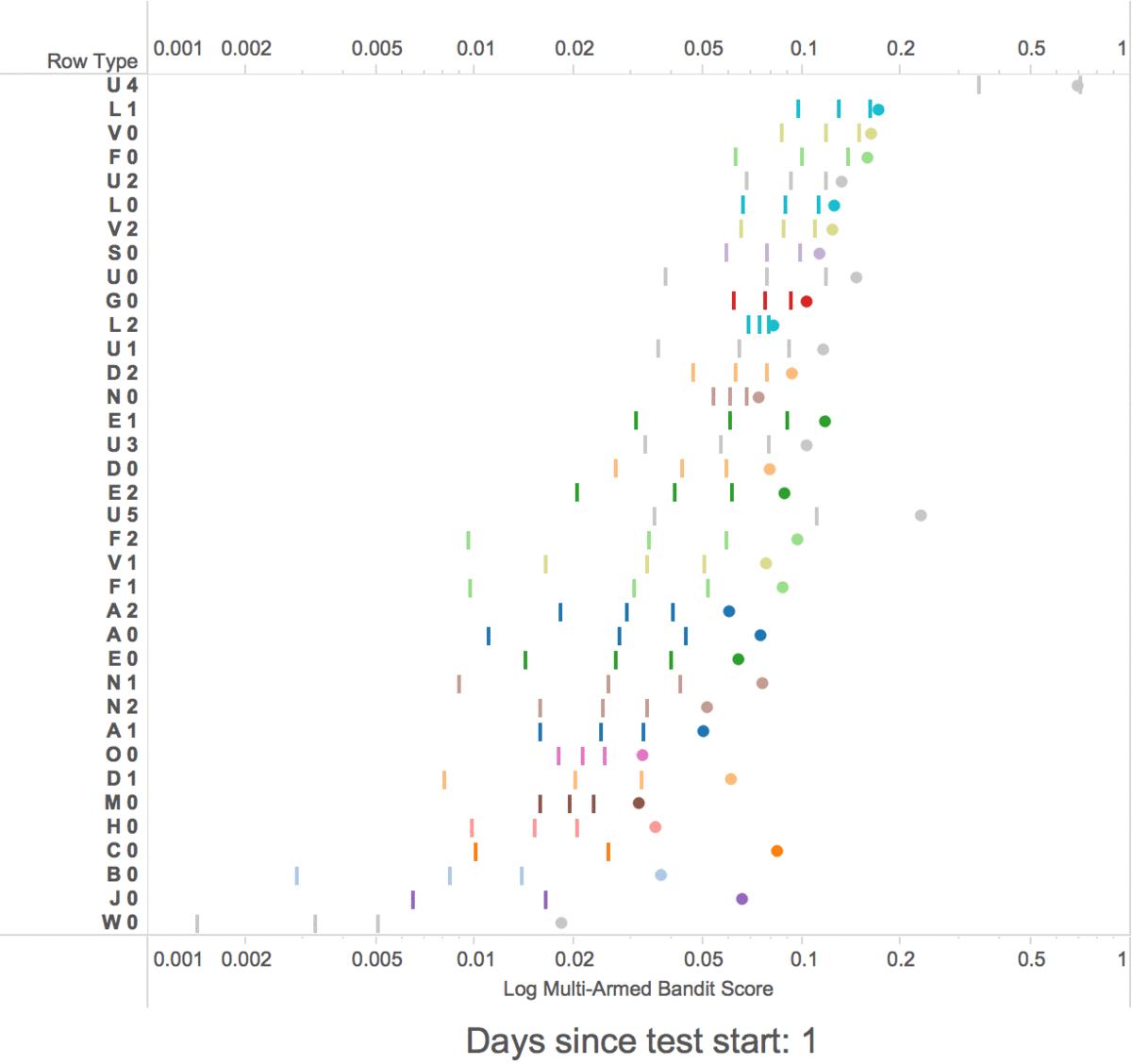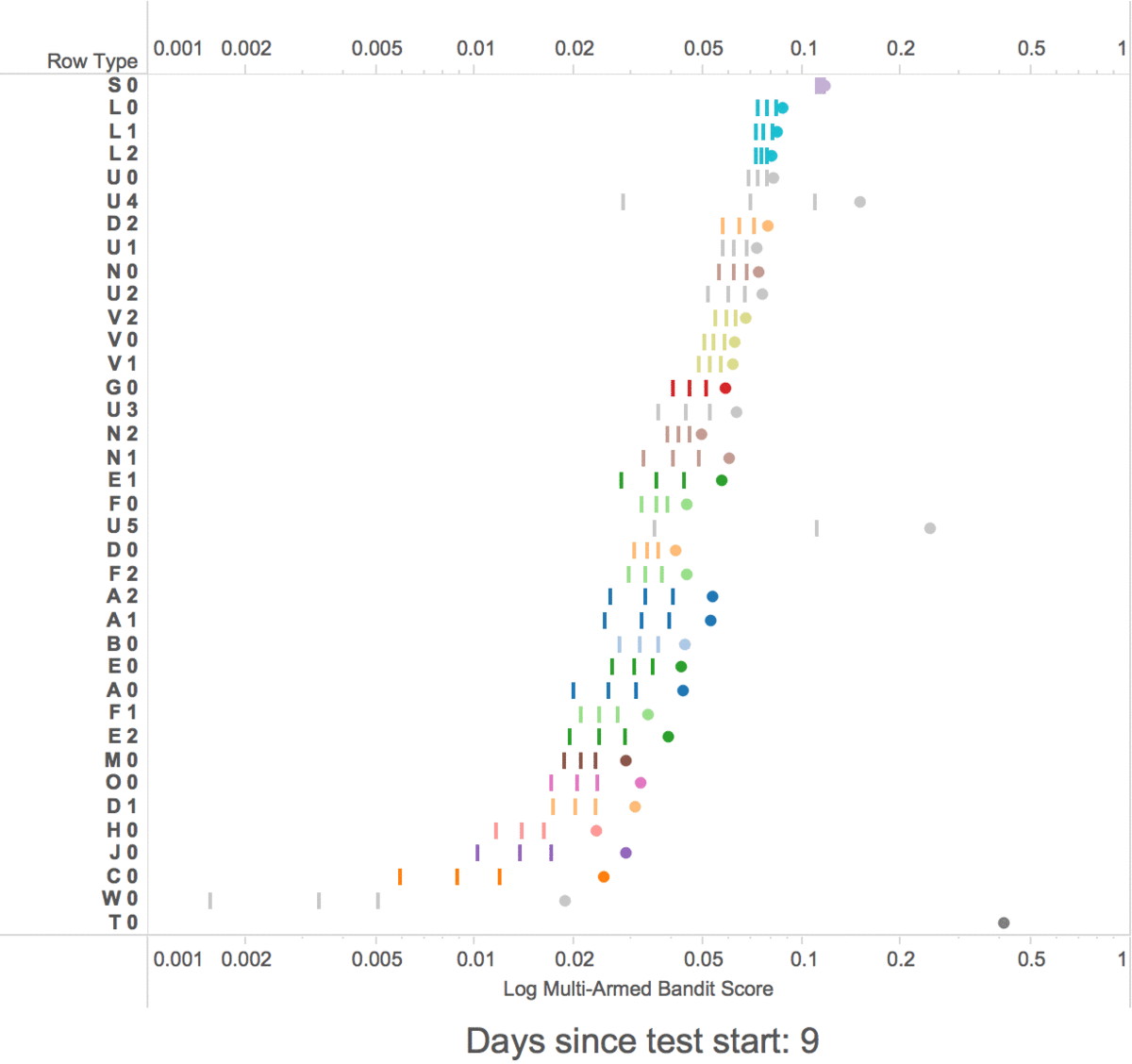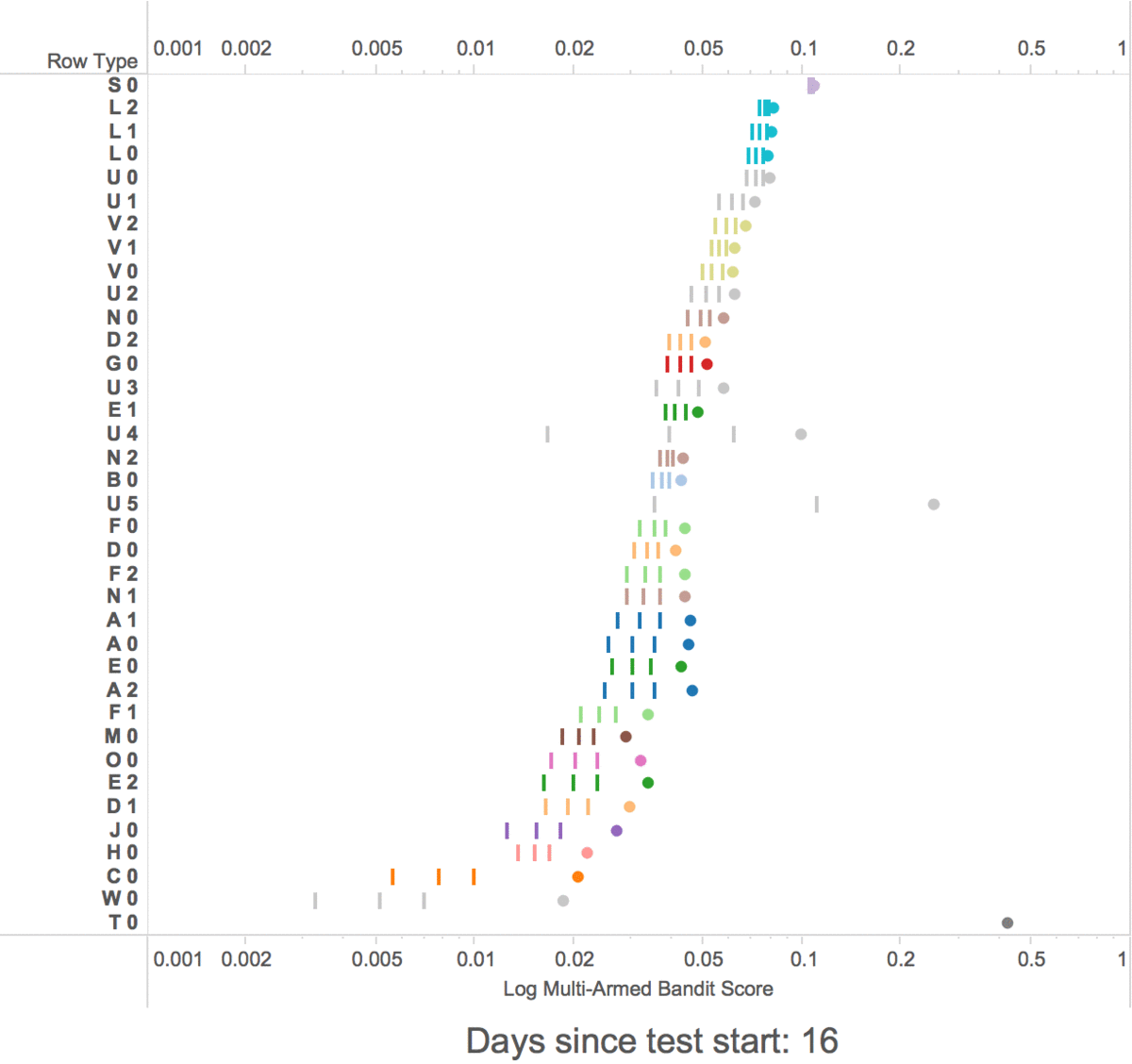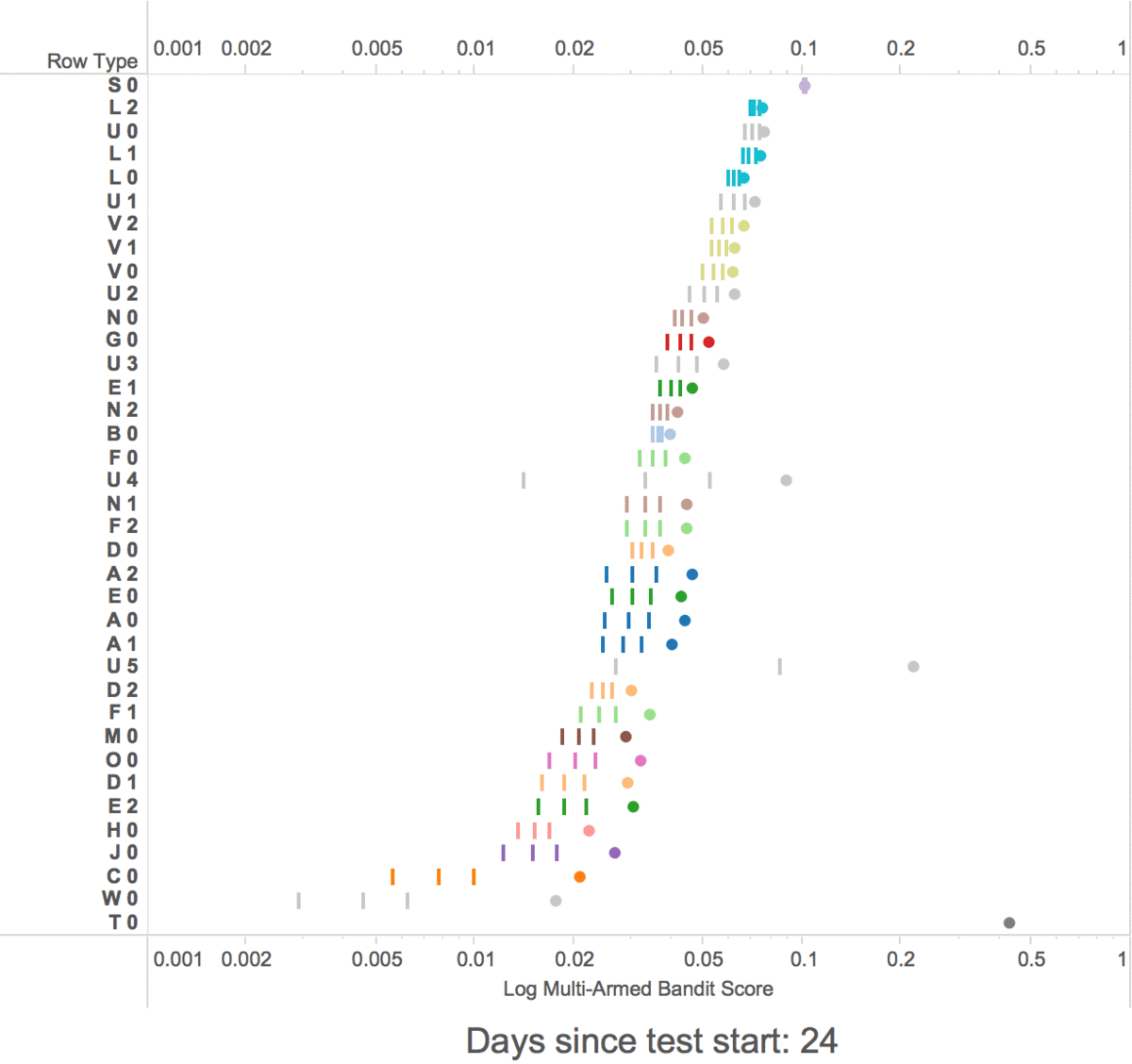
-
The 3 lines are the confidence interval for each row type
- The dots are the scores + the bonus
Insights from the multi-armed bandit
-
The multi-armed bandit increased activity from the best performing row by 4X.
-
We learned that users like to see the content they have saved in their recommendations, which helps inform future product decisions about saving content.
- The multi-armed bandit learned which rows performed the best and adjusted their placement accordingly.
Putting it all together
We took you through the process from start to finish on how we iterated our home page by running a few tests, incorporating user feedback and using an algorithmic approach to find the optimal solution. While we made good progress on this, we’ll continue working on how we generate and rank the candidate items for each row as we work to create a better user experience. More generally, we’ll continue to leverage multi-armed bandits, including contextual bandits, to deliver a personalized experience for our users.