We designed and implemented a scalable, cost-optimized backup system for S3 data warehouses that runs automatically on a monthly schedule. The system handles petabytes of data across multiple databases and uses a hybrid approach: AWS Lambda for small workloads and ECS Fargate for larger ones. At its core, the pipeline performs incremental backups — copying only new or changed parquet files while always preserving delta logs — dramatically reducing costs and runtime compared to full backups. Data is validated through S3 Inventory manifests, processed in parallel, and stored in Glacier for long-term retention. To avoid data loss and reduce storage costs, we also implemented a safe deletion workflow. Files older than 90 days, successfully backed up, and no longer present in the source are tagged for lifecycle-based cleanup instead of being deleted immediately. This approach ensures reliability, efficiency, and safety: backups scale seamlessly from small to massive datasets, compute resources are right-sized, and storage is continuously optimized.
Our old approach had problems:
- Copying over the same files all the time – not effective from a cost perspective
- Timeouts when manifests were too large for Lambda
- Redundant backups inflating storage cost
- Orphaned files piling up without clean deletion
We needed a systematic, automated, and cost-effective way to:
- Run monthly backups across all databases
- Scale from small jobs to massive datasets
- Handle incremental changes instead of full copies
- Safely clean up old data without risk of data loss
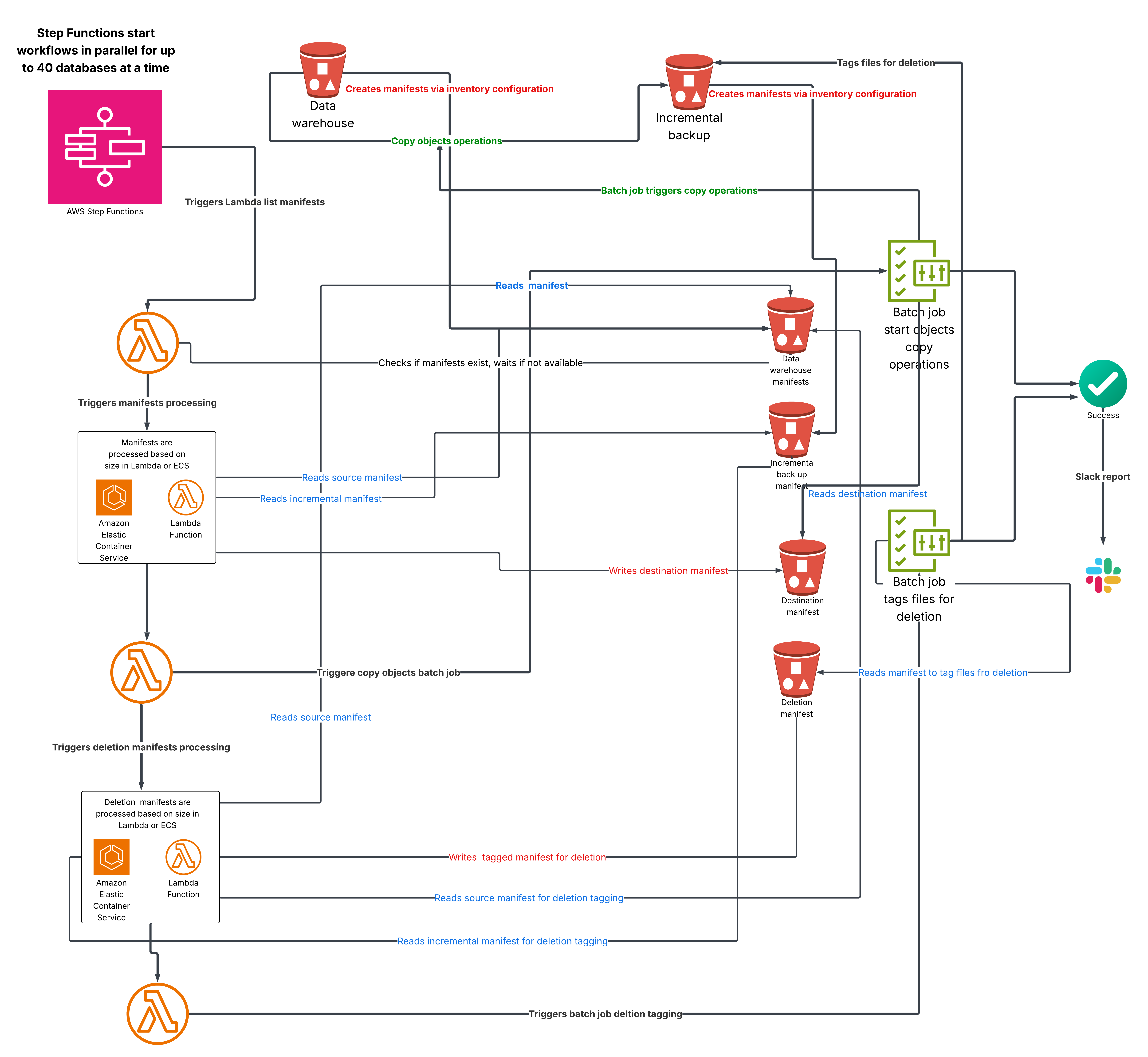
The Design at a Glance
We built a hybrid backup architecture on AWS primitives:
- Step Functions – orchestrates the workflow
- Lambda – lightweight jobs for small manifests
- ECS Fargate – heavy jobs with no timeout constraints
- S3 + S3 Batch Ops – storage and bulk copy/delete operations
- EventBridge – monthly scheduler
- Glue, CloudWatch, Secrets Manager – reporting, monitoring, secure keys
- IAM – access and roles
The core idea: Do not copy file what are already in back up and copy over always delta log, Small manifests run in Lambda, big ones in ECS.
How It Works
-
Database Discovery
Parse S3 Inventory manifests
Identify database prefixes
Queue for processing (up to 40 in parallel) -
Manifest Validation
Before we touch data, we validate:
- JSON structure
- All CSV parts present
- File counts + checksums match
If incomplete → wait up to 30 minutes before retry
-
Routing by Size
- ≤25 files → Lambda (15 minutes, 5GB)
- 25 files → ECS Fargate (16GB RAM, 4 vCPUs, unlimited runtime)
-
Incremental Backup Logic
- Load exclusion set from last backup
- Always include delta logs
- Only back up parquet files not yet in backup
- Ignore non-STANDARD storage classes (we use Intelligent-Tiering; over time files can go to Glacier and we don’t want to touch them)
- Process CSVs in parallel (20 workers)
- Emit new manifest + checksum for integrity
-
Copying Files
- Feed manifests into S3 Batch Operations
- Copy objects into Glacier storage
-
Safe Deletion
- Compare current inventory vs. incremental manifests
- Identify parquet files that:
- Were backed up successfully
- No longer exist in source
- Are older than 90 days
- Tag them for deletion instead of deleting immediately
- Deletion is performed using S3 lifecycle configuration for cost-optimized deletion
- Tags include timestamps for rollback + audit
Error Handling & Resilience
- Retries with exponential backoff + jitter
- Strict validation before deletes
- Exclusion lists ensure delta logs are never deleted
- ECS tasks run in private subnets with VPC endpoints
Cost & Performance Gains
- Incremental logic = no redundant transfers
- Lifecycle rules = backups → Glacier, old ones cleaned
- Size-based routing = Lambda for cheap jobs, ECS for heavy jobs
- Parallelism = 20 CSV workers per manifest, 40 DBs at once
Lessons Learned
- Always validate manifests before processing
- Never delete immediately → tagging first saved us money
- Thresholds matter: 25 files was our sweet spot
- CloudWatch + Slack reports gave us visibility we didn’t have before
Conclusion
By combining Lambda, ECS Fargate, and S3 Batch Ops, we’ve built a resilient backup system that scales from small to massive datasets. Instead of repeatedly copying the same files, the system now performs truly incremental backups — capturing only new or changed parquet files while always preserving delta logs. This not only minimizes costs but also dramatically reduces runtime.
Our safe deletion workflow ensures that stale data is removed without risk, using lifecycle-based cleanup rather than immediate deletion. Together, these design choices give us reliable backups, efficient scaling, and continuous optimization of storage. What used to be expensive, error-prone, and manual is now automated, predictable, and cost-effective.