
With Delta Lake we don’t have the lines between streaming and batch data typically found in data platforms. Scribd developers can treat data as real-time as they wish! Delta Lake enables some workloads to treat data sets like they are traditional “batchy” data stores, while other workloads work with the same data as a streaming source or sink. This immense flexibility allows our data engineers and scientists to mix and match data quickly, providing the business with valuable results at unprecedented speed.
At its core Delta Lake combines Apache Parquet with a transaction log. This simple foundation enables incredible higher level data-access behaviors from Apache Spark, which powers the vast majority of our data platform at Scribd. When we first considered building a Real-time Data Platform the storage layer was “to be determined”. In hindsight, I cannot imagine how a team of less than ten developers could have successfully delivered on the “Real-time” vision in so short a time. Much of that success rests on adopting Delta Lake, and in this post I would like to share some of the motivations, valuable features, and perhaps most importantly caveats to adopting Delta Lake for streaming data needs.
Beforetimes
Storage is the most foundational component of a data platform, and we were in bad shape at the beginning of effort. The original storage layer was built on top of HDFS, which was a very reasonable decision at the time. Unfortunately as the years went on, our use of HDFS did not keep up with the times. Technical debt accrued in many forms:
- Uncompressed data
- Multiple different file types, depending on what era a partition of data was written in, it might be Parquet, ORC, RCFile, or just dumb plaintext.
- Small files, over 60% of the files in the cluster were considered “small files”.

The storage layer was failing to meet our batch needs well before we had even considered layering streaming data on top of it.
Welcome to the future
Delta Lake solved a lot of the problems we had, and even a few we did not know we had yet! We adopted Delta Lake inline with our shift into the cloud, which I recently wrote about on the Databricks blog: Accelerating developers by ditching the data center. Yet, Delta Lake wasn’t our first choice and didn’t motivate our shift to AWS. Our original prototype consisted of writing Parquet files to S3, where we immediately noticed potential problems.
Data Consistency
S3 is eventually consistent. If you create an object bucket/foo.gz, you can
retrieve bucket/foo.gz immediately, but other clients issuing list or
metadata commands may see foo.gz appear at different times. In a system where
one job is writing data into a bucket and another is reading data out of that
bucket, consistency becomes a major concern. Many organizations solve this
by deploying
S3Guard
which helps address the problem. Delta Lake provides us with ACID transactions
that make the entire data consistency question moot.
What I wrote to storage is exactly what the other job will read
Streaming to Delta
Delta Lake makes building a streaming platform almost trivial with two key higher level behaviors: streaming sinks and sources. Like practically any data store you can stream data into a Delta table, though Delta’s transactions make this a much safer operation when deploying on eventually consistent data stores like S3. Delta tables can however also act as a source for another streaming consumer.
In Scribd’s deployment, this allows us to have some Spark Streaming jobs which are consuming directly from Apache Kafka, while other downstream streaming jobs consume from Delta tables themselves.
My previous post alluded to the “View Analytics” project, which relies heavily on Delta Lake’s streaming support:
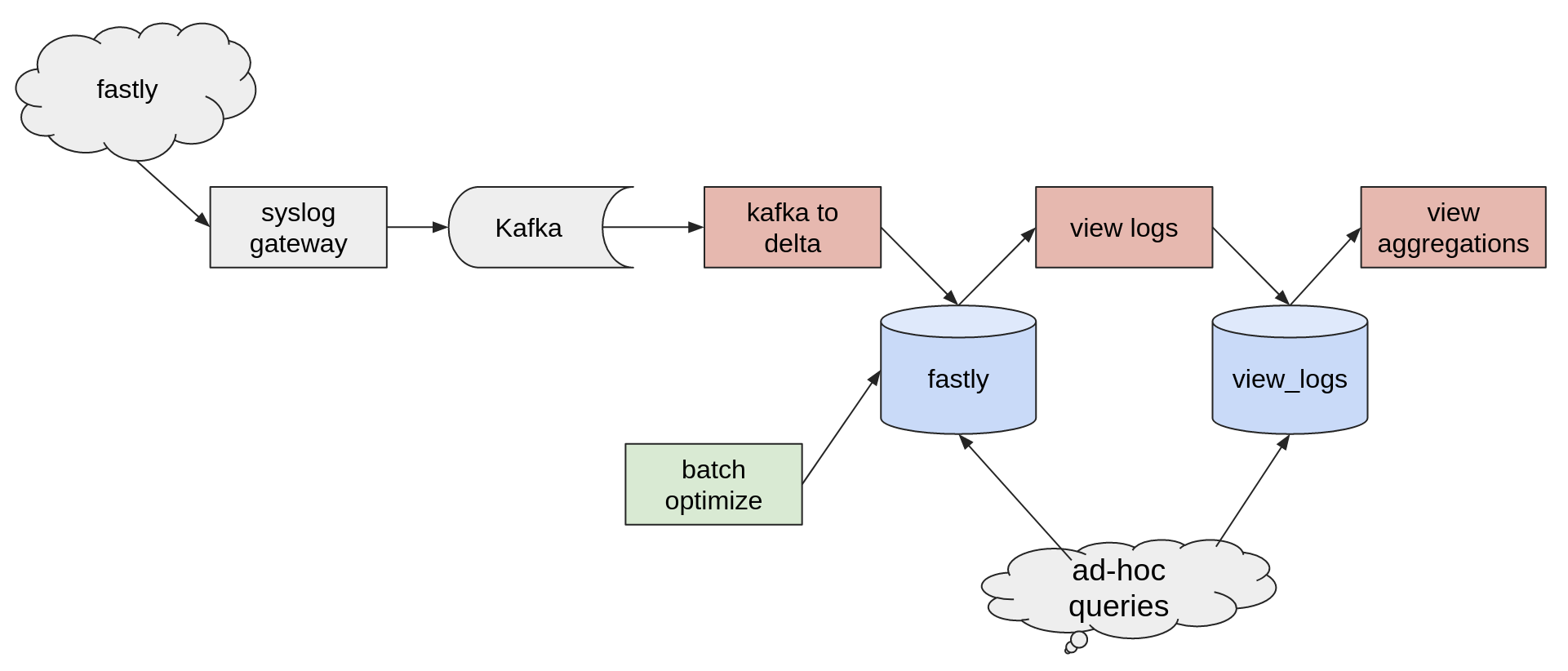
By utilizing Delta tables as streaming sources in the pipeline above, we enable ad-hoc and other batch workloads to query data within the pipeline as if it were just another table in the catalog. This is key for us because it means many of our data consumers are only interacting with Delta tables, rather than having to switch between pulling data from Kafka topics and separately from batch tables. Delta Lake allows the data consumers to treat them all as just tables, although some are a little more real-time than others!
Caveats
Delta tables within a streaming context do have some limitations which are important to be aware of when designing a system. Many of our lessons learned came by partnering with Databricks during the design phase of the View Analytics project. Fortunately they were able to identify some ways in which our original designs would have failed before we ended up building and deploying anything to production.
Some things to keep in mind:
- Multiple streams can append to the same table concurrently, but if there are any non-append writers (e.g. merge writers) then no other writers should run concurrently with the non-append writer. There are some distinctions here depending on whether the jobs are running in a Databricks runtime or not, and whether those jobs are running in the same workspace. Generally speaking it’s best to only use append-only tables as streaming sources.
- When there are any non-append writers, an optimize cannot run externally. In essence it should be executed inline in a streaming job when the merge writer is not running, i.e. periodically within a
foreachBatch. Locking features only available in the Databricks runtime may allow for concurrent upsert writers, but your mileage may vary! - Checkpoints must be managed carefully. each checkpoint location should belong exclusively to a single write stream. restarts of the job must always use the same checkpoint location. do not reference the same checkpoint location from multiple write streams as they will overwrite each others checkpoints (very bad).
Optimize
Building further upon the foundation laid by transactions, Delta Lake provides
an OPTIMIZE command, which helps prevent the small files problem entirely.
In the streaming context, it is highly unlikely that event data will come in perfectly even-sized batches that can be written to storage. At a high level, when the optimize command is run it will:
- Create a new transaction
- Take a bunch of small files
- Combine them together as larger, well-sized and compressed files
- Write those to storage
- Completes the transaction.
This can all be done online which means whatever data is streaming into the table can continue to stream.
NOTE: Since optimize doesn’t delete those small files after it operates, periodic vacuum commands are necessary to reduce storage bloat.
General caveats
Delta Lake is a great piece of technology for streams and batch workloads alike, regardless of how it is used, there are some general limitations to bear in mind. Perhaps the most notable is that it can/should only be accessed from Apache Spark. This usually means that a Spark cluster must be launched in order to read or write from Delta tables, and the corresponding costs associated with that should be known. While there are efforts to provide client APIs external to Spark, nothing yet exists which is production ready.
We are Databricks customers, which means we’re actually using the proprietary Delta libraries which are include in the Databricks Spark runtimes. In our testing and development we have observed a number of important gaps between what is available in the open source delta.io client libraries, compared to what is present in the Databricks version. These gaps have mostly affected our ability to do fully local testing, dictating a certain amount of manual testing for Spark streaming jobs launched in Databricks, before they are deployed to production.
There are a number of other caveats when using Delta that are important to be aware of, and while I cannot cite every single one here I will stress: read the documentation thoroughly. There are a number of callouts in the docs which highlight a constraint or behavior which will impact the design of streaming systems you may build on Delta Lake. Very little of what we learned working with Databricks was not documented, in almost all cases we had misread, misunderstood, or simply missed a salient detail in the documentation.
We started working on the real-time data platform in January, our first production streaming workloads were deployed by March. Adopting Delta Lake allowed us to move quickly and deploy streaming systems at an incredible pace. For a company that has a long history of batch workloads, the sudden arrival of streaming data has been transformative. Rather than waiting 24-48 hours for data in some cases, data consumers are able to access newly written data within seconds.