
When we set our goals at the beginning of the year “deploy Rust to production” was not among them, yet here we are. Our pattern of deploying small services in containers allowed us to easily bring Rust into production, replacing a difficult to manage service in the process. In January, the Core Platform team started working on a project called “View Analytics”. The effort was primarily to replace an aging system which was literally referred to as “old analytics.” As part of the View Analytics design we needed to provide an entry point for Fastly to relay access logs as syslog formatted messages which could then be written into Apache Kafka, driving the entire View Analytics data pipeline. Our initial rollout shipped an rsyslog-based solution for the “rsyslog-kafka” service.. Using rsyslogd worked fairly well, but had a couple of significant downsides. Last month, we deployed its replacement: a custom open source daemon written in Rust: hotdog 🌭.
(Note: This specific use-case was well suited to Rust. That does not mean that anything else we do at Scribd should or will necessarily be written in Rust.)
Problems with rsyslog
rsyslog is one of those tools that seems to have existed since the dawn of
time. It is incredibly common to find in logging infrastructure since it routes
just about any log from any thing, to any where. Our first iteration of the
aforementioned rsyslog-kafka service relied on it because of its ubiquity. We
had a problem that looked like routing logs from one thing (Fastly) to another
thing (Kafka), and that’s basically what rsyslogd does!
However, when explaining to colleagues what rsyslog
really is, I would describe it as “an old C-based scripting engine that just
happens to forward logs.” If they didn’t believe me, I would send them the
documentation to
Rainerscript, named
after Rainer Gerhards, the
author of rsyslog. I find it incredibly difficult to work with, and even harder to test.
In our pipeline, we needed to bring JSON formatted messages from Fastly and route them to the appropriate topics, using the approximate format of:
{
"$schema" : "some/jsonschema/def.yml",
"$topic" : "logs-fastly",
"meta" : {
},
"url" : "etcetc",
"timestamp" : "iso8601"
}
JSON parsing in rsyslog is feasible, but not easy. For example, there
is no way to handle JSON keys which use the dollar-sign $, because the
scripting interpreter treats $ characters as variable references. The
original version of our rsyslog-kafka gateway that went into production
uses regular expressions to fish out the topic!
Unfortunately, the daemon also does not emit metrics or statistics natively in a format we could easily get into Datadog. The only way to get the statistics we needed would be to ingest statistics written out to a file through a sidecar container and report those into Datadog. This would have required building a custom daemon to parse the rsyslogd stats output which seemed like a lot of work for a little bit of benefit.
We didn’t know how this difficult and untestable service would actually run in production.
Makin’ hotdogs
Bored one weekend with nothing to do, I asked myself “how hard could getting syslog into Kafka be?” As it turned out: not that hard.
I continued to improve hotdog over a number of weeks until I had feature parity with our rsyslogd use-case, and then some!
- RFC 5424/3164 syslog-formatted message parsing
- Custom routing based on regular expression or JMESPath rules
- syslog over TCP, or TCP with TLS encryption
- Native statsd support for a myriad of operational metrics we care about
- Inline message modification based on simple Handlebars templates
Since the rsyslog-kafka service is deployed in a Docker container, we deployed a new build of the container with 🌭 inside to our development environment and started testing. After testing looked to be going well, we deployed to production at the end of May.
Overall the process went well!
What was learned
The biggest take-away from this effort has been the power of small services packaged into Docker containers. The entire inside of the container changed, but because the external contracts were not changed the service could be significantly modified without issue.
The original implementation was ~2x slower than rsyslog and required a doubling of the number of containers running in ECS. The poor performance almost entirely came to laziness in the original Rust implementation. Repeated parsing of JSON strings, reallocations, and unnecessary polling.
The performance issues were easily identified and fixed with the help of the
perf on Linux (perf record --call-graph dwarf is wonderful!) That said, I
am still quite impressed that a completely unoptimized Rust daemon, built on
async-std, was performing reasonably close to a
finely-tuned system like rsyslogd. While I haven’t done a conclusive
comparison, now that hotdog has been optimized I would guesstimate that it is
with +/-10% performance parity rsyslogd.
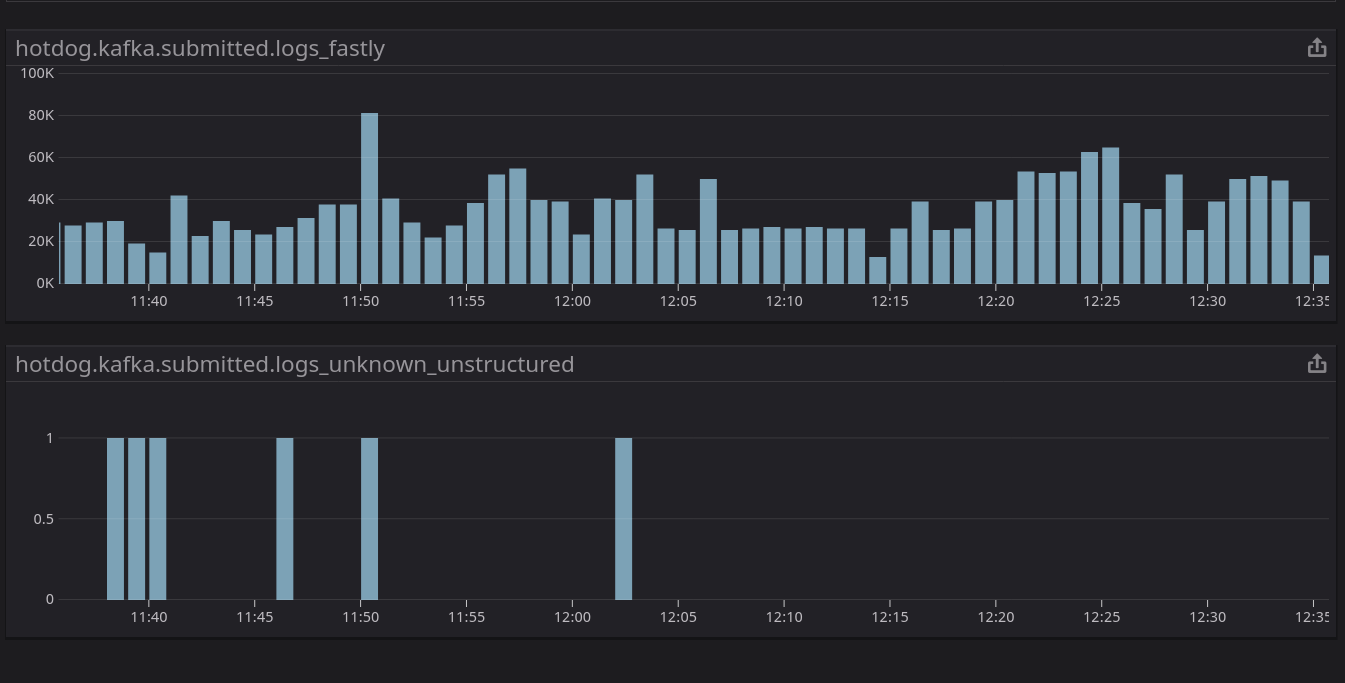
Having full control over the syslog entrypoint proved valuable almost
immediately. During a pairing session with my colleague Hamilton, he expressed the
desire for an additional metric: per-topic message submission counters. In
rsyslogd the metric doesn’t exist in any form, but because hotdog was built to
support statsd out of the box, we made a one-line change adding the new metric
and our visibility went up almost immediately!
The syslog-to-Kafka gateway was a critical piece of the overall View Analytics data pipeline, but having such a system available has already paid dividends. A number of other internal projects have taken advantage of the ability to route syslog traffic into Kafka.
Scribd has a number of services deployed in production using Ruby, Golang, Python, Java, and now a little bit of Rust too. As far as weekend hacks go, hotdog worked out quite well, if you have thousands of log entries per second that you need to get into Kafka, give it a try!