
Scribd recently changed the way we run thousands of data-processing tasks in order to save 10-20% more on our cloud compute costs. Scribd’s data platform is built on top of Databricks on AWS and runs 1500+ Apache Spark batch and streaming applications. To help orchestrate all the batch workloads we also use Apache Airflow. By default, Databricks provides a rich set of cluster configuration options. We can use different EC2 instance types, AWS Availability Zones (AZ), spot or on-demand instances, autoscaling, etc. By examining the needs of our workloads, we were able to optimize the way we leverage Databricks and AWS to gain more reliability and 10-20% more cost savings in our data platform.
For most clusters which run our batch workloads, we use auto-scaling and spot instances, falling back to on-demand instances. Theoretically, this helps us to save up to 90% on cloud infrastructure. But in the real world using spot instances has some limitations, problems, areas for optimization. In this post, I will share some tips that we use for an optimized Databricks cluster configuration.
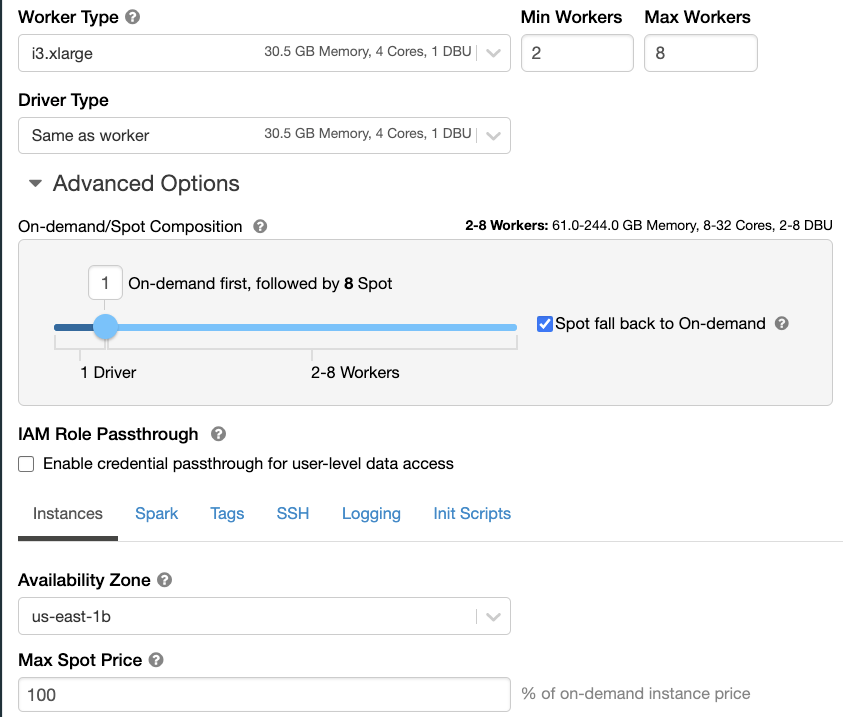
First, let’s review some of the problems we encounter with an “out of the box” Databricks cluster configuration:
- EC2 spot prices are not static across availability zones (AZs). Sometimes price grows up to an on-demand price.
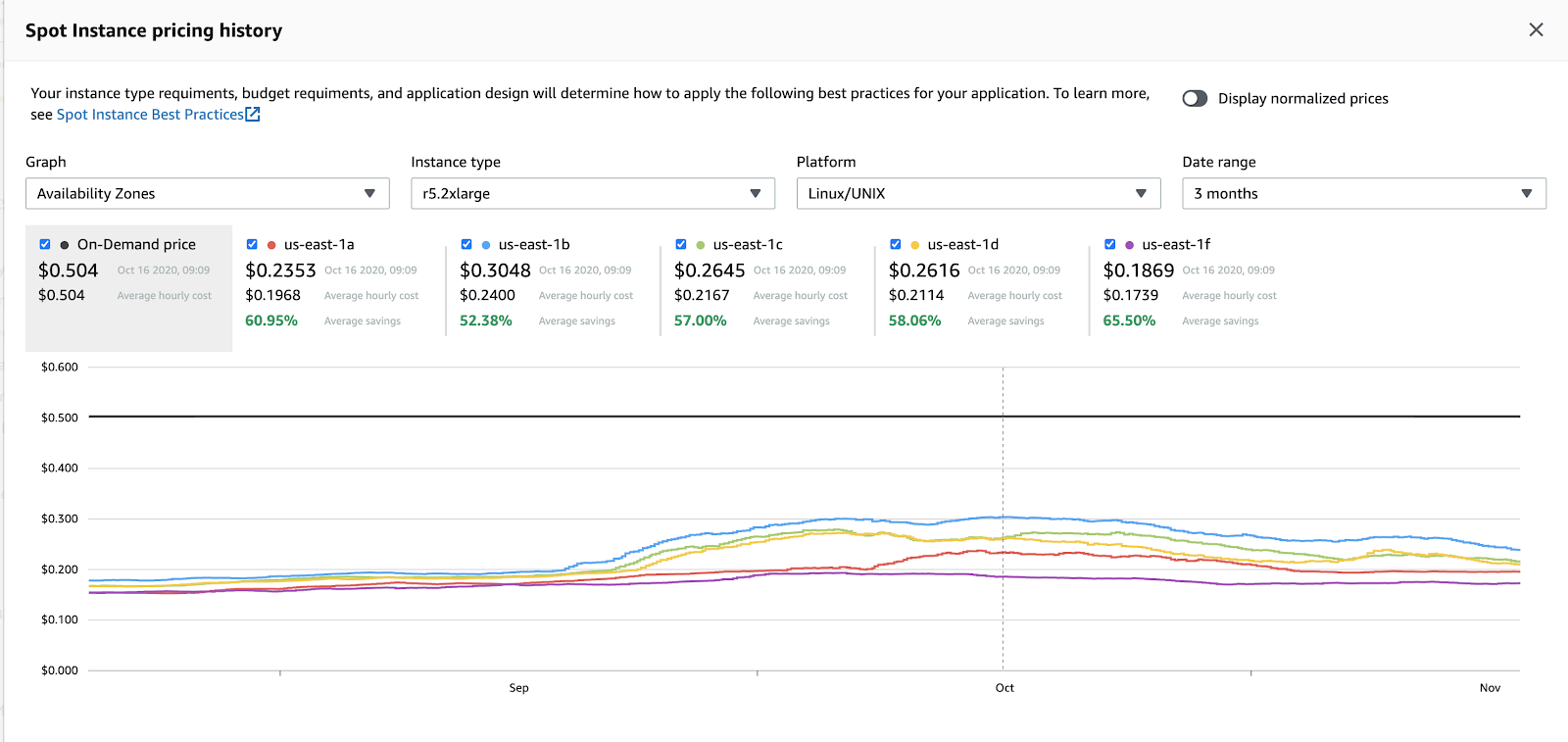
-
AWS has a limited number of instances for each AZ. When instances for some type are not available AWS throws an exception: “We currently do not have sufficient
capacity in the Availability Zone you requested”. -
In a Databricks cluster, we must use a predefined cluster configuration with a specified instance type and AZ. It’s not possible to apply some fallback algorithm when the requested instances are not available in the desired AZ.
To address these problems, we set the following goal: We need to be flexible about instance types, availability zones, and provide a fallback mechanism when instances are not available. Unfortunately, we are not able to solve these problems in the Databricks platform alone. Since our primary interface to Databricks for automated workloads is Apache Airflow, we can customize our Airflow operators to achieve the goal!
How it works.
In Airflow we use our own DatabricksSparkOperator. In this operator, we set up a cluster configuration which Airflow can then use when submitting jobs to Databricks.
For cluster configuration, we offer two different sets of parameters, one to describe instance types desired for the workload, and the other which describes the Spark execution environment needed by the workload. Each set is handled by a different optimization strategy:
The instance-based configuration contains a couple key parameters:
node_type_id, and AWS instance typenum_workers, the minimum/maximum workers for auto-scaling.
To optimize these workloads we use a very simple algorithm based on the DescribeSpotPriceHistory API. We extract all AZs for requested instance type in a specific AWS region and sort these zones by the current spot price (from the cheapest to the most expensive zone). After that, we request Databricks clusters in the first zone from the list (the cheapest). If AWS doesn’t have enough capacity for a particular instance type in the first AZ we apply fallback and try the next one.
There are a few reasons to try the cheapest zone first. First - it saves up to 10% of our AWS costs. Second - most of the time AWS provides the cheapest price in AZ with a lot of unused spot instances, helping us avoid insufficient capacity errors.
The Spark-execution environment configuration uses different parameters for describing the needs of the Spark job:
executor_memoryexecutor_coresnum_workers, or minimum/maximum number of workers for auto-scaling.
For jobs using these parameters, we apply a separate algorithm: using executor_memory and executor_cores parameters to find all possible instance types that have enough capacity (num of cores >= executor_cores, memory >= num of cores * executor_memory / executor_cores), calculate the number of workers (for large instance types we can decrease num_workers value) and the cluster total costs (num_workers * (current AWS spot price + Databricks price)). We sort all possible combinations by the cluster totals cost value, memory, ECU and after that, we request a Databricks cluster for the first instance type in the list. If instances for this type are not available we apply fallback and try the next option in the list.
Using this strategy we may save an extra 10% (compared to the first strategy) and have fewer problems with spot instances availability, because we use a different instance type in a different AZ.
These two simple strategies help us to achieve our goal of being flexible with instance types and avoiding capacity problems.
Below you can find examples for each strategy.
Strategy 1: node_type_id = m5.xlarge, num_workers = 100:
DatabricksSparkOperator uses AwsBaseHook to requests spot instance prices for instance-type=m5.xlarge, product-description=Linux/UNIX (Similar request with AWS cli looks like:
aws ec2 describe-spot-price-history --instance-type=m5.xlarge --start-time=$(date +%s) --product-descriptions="Linux/UNIX" --query 'SpotPriceHistory[*].{az:AvailabilityZone, price:SpotPrice}'
AWS Response:
{ "az": "us-east-2a", "price": "0.042300" }
{ "az": "us-east-2c", "price": "0.041000" }
{"az": "us-east-2b", "price": "0.040800" }
In this situation, we try to request 100 m5.xlarge instances in AZ us-east-2b. If AWS doesn’t have enough capacity in this zone, the DatabricksSparkOperator applies a fallback procedure and request cluster in us-east-2c.
Strategy 2: executore_cores = 4, executor_memory = 8G, num_workers = 100
DatabricksSparkOperator requests spot instance prices for instance-types that have more than 4 cores and more than 2Gb of memory per core from the list of possible instance types.
AWS Response contains a lot of different instance types and AZ, but let me truncate this list and leave only a few rows:
{ "az": "us-east-2a", "price": "0.042300", "instance_type": m5.xlarge" }
{ "az": "us-east-2c", "price": "0.045000", "instance_type": m5.2xlarge" }
{ "az": "us-east-2c", "price": "0.045000", "instance_type": r5.2xlarge" }
We also need to include the cost of Databricks, for ease of calculation, we assume that 1 DBU = $0.1.
Databricks prices:
- M5.xlarge (0.69 DBU/Hr)
- m5.2xlarge(1.37 DBU/Hr)
- r5.2xlarge(1.37 DBU/Hr)
We calculate cluster total cost using formula:
Results:
{ "az": "us-east-2a", "price": "0.042300", "instance_type": "m5.xlarge", "num_of_worker" = 100, "total_cost" = "0.29187" }
// Below clusters require only 50 workers, because 2xlarge instance types have 8 cores and more than 2GB/core
{ "az": "us-east-2c", "price": "0.045000", "instance_type": "m5.2xlarge", "num_of_worker" = 50, "total_cost" = "0.30825"}
{ "az": "us-east-2c", "price": "0.045000", "instance_type": "r5.2xlarge","num_of_worker" = 50, "total_cost" = "0.30825"}
So, in this situation we try to request 100 m5.xlarge instances in us-east-2a, then 50 r5.2xlarge instances in AZ us-east-2c (total price is similar to m5.2xlarge, but r5 instances has 2x memory for the same money), after that 50 m5.2xlarge in AZ us-east-2c.
After experimenting with this change , we rolled it into our production Airflow environment and are already seeing more reliable job execution and have not seen noticeable impact to batch job performance. There are dozens of ways to optimize data platform costs in the cloud, but a good place to start is by looking at what your workloads actually need!
On the Core Platform and Data Engineering teams we continue to invest in Spark\Airflow and would love your help building out our reliable and high-performance data platform, come join us!