
Streaming data from Apache Kafka into Delta Lake is an integral part of Scribd’s data platform, but has been challenging to manage and scale. We use Spark Structured Streaming jobs to read data from Kafka topics and write that data into Delta Lake tables. This approach gets the job done but in production our experience has convinced us that a different approach is necessary to efficiently bring data from Kafka to Delta Lake. To serve this need, we created kafka-delta-ingest.
The user requirements are likely relatable to a lot of folks:
- My application emits data into Kafka that I want to analyze later.
- I want my Kafka data to land in the data warehouse and be queryable pretty soon after ingestion.
Looking around the internet, there are few approaches people will blog about but many would either cost too much, be really complicated to setup/maintain, or both. Our first Spark-based attempt at solving this problem falls under “both.”
Spark Structured Streaming is a powerful streaming framework that can easily satisfy the requirements described above with a few lines of code (about 70 in our case) but the cost profile is pretty high. Despite the relative simplicity of the code, the cluster resources necessary are significant. Many of our variable throughput Kafka topics leave us wishing for auto-scaling too.
Kafka Delta Ingest is an open source daemon created by Scribd in the Delta Lake project with the very specific goal of optimizing the path from Kafka to Delta Lake. By focusing on this very specific use-case, we can remove many of the pain points we currently experience with our Spark streaming jobs. The daemon is written in Rust which has helped us keep the runtime super efficient. It is also fully distributed with no coordination between workers, meaning no driver node hanging out and a smaller overall infrastructure footprint.
In depth
There is a bit of an impedance mismatch between Kafka streams and data warehouse file structure. Parquet is a columnar format, and each Parquet file (in fact each row group within a file) in a Delta Lake table should include a lot of rows to enable queries to leverage all the neat optimization features of parquet and run as fast as possible. Messages consumed from a Kafka topic come in one at a time though. To bridge this mismatch, Kafka Delta Ingest spends most of its time buffering messages in memory. It checks a few process arguments to make the largest possible parquet files. Those arguments are:
- allowed_latency - the latency allowed between each Delta write
- max_messages_per_batch - the maximum number of messages/records to include in each Parquet row group within a file
- min_bytes_per_file - the minimum bytes per parquet file written out by Kafka Delta Ingest
Internally, our internal Kafka usage guidelines include these constraints:
- Messages written to Kafka
- Must be JSON
- Must include an ISO 8601 timestamp representing when the message was ingested/created (field name is flexible, but this timestamp must be included somewhere in the message)
- Records written to Delta Lake
- Must include Kafka metadata
- We preserve the metadata fields below under a struct field called
meta.kafka- topic
- partition
- offset
- timestamp
- We preserve the metadata fields below under a struct field called
- Must include a date-based partition (e.g. yyyy-MM-dd) derived from the ISO 8601 ingestion timestamp of the message
- Must include Kafka metadata
Other potential users of Kafka Delta Ingest may have different guidelines on how they use Kafka. Because of how we use Kafka internally, the first iteration of Kafka Delta Ingest is very focused on:
- JSON formatted messages
- Buffer flush triggers that thread the needle between query performance and persistence latency
- Very basic message transformations to limit the message schema constraints we push up to our producer applications
Example
Let’s say we have an application that writes messages onto a Kafka topic called
web_requests every time it handles an HTTP request. The message schema
written by the producer application includes fields such as:
status: 200, 404, 500, 302, etc.method:GET,POST, etc.url: Requested URL, e.g./documents/42, etc.meta.producer.timestamp: an ISO-8601 timestamp representing the time the producer wrote the message.
Many of our tables are partitioned partitioned by a field called date which
has a yyyy-MM-dd format. We choose not to force our producer application to
provide this field explicitly. Instead, we will configure our Kafka Delta
Ingest stream to perform a transformation of the meta.producer.timestamp
field that the producer already intends to send.
To accomplish this with Kafka Delta Ingest, using the “web_requests” stream as an example, we would:
- Create the “web_requests” topic
- Create the schema for our Delta Lake table:
CREATE TABLE `kafka_delta_ingest`.`web_requests` ( `meta` STRUCT< `kafka`: STRUCT<`offset`: BIGINT, `topic`: STRING, `partition`: INT>, `producer`: `timestamp` >, `method` STRING, `status` INT, `url` STRING, `date` STRING ) USING delta PARTITIONED BY (`date`) LOCATION 's3://path_to_web_requests_delta_table'The Delta Lake schema we create includes more fields than the producer actually sends. Fields not written by the producer include the
meta.kafkastruct and thedatefield. - Launch one or more kafka-delta-ingest workers to handle the topic-to-table pipeline:
kafka-delta-ingest ingest web_requests s3://path_to_web_requests_delta_table \ -l 60 \ -K "auto.offset.reset=earliest" \ -t 'date: substr(meta.producer.timestamp, `0`, `10`)' \ 'meta.kafka.offset: kafka.offset' \ 'meta.kafka.partition: kafka.partition' \ 'meta.kafka.topic: kafka.topic'
The parameters passed to the daemon configure the allowed latency, some primitive data augmentation, the source topic, and the destination Delta table. For more detailed documentation, consult the readme.
Internally, Kafka Delta Ingest relies on Kafka consumer groups to coordinate partition assignment across many workers handling the same topic. If we want to scale out the number of workers handling “web_requests” we can just launch more ECS tasks with the same configuration and respond to Kafka’s rebalance events.
The deployment ends up looking like:
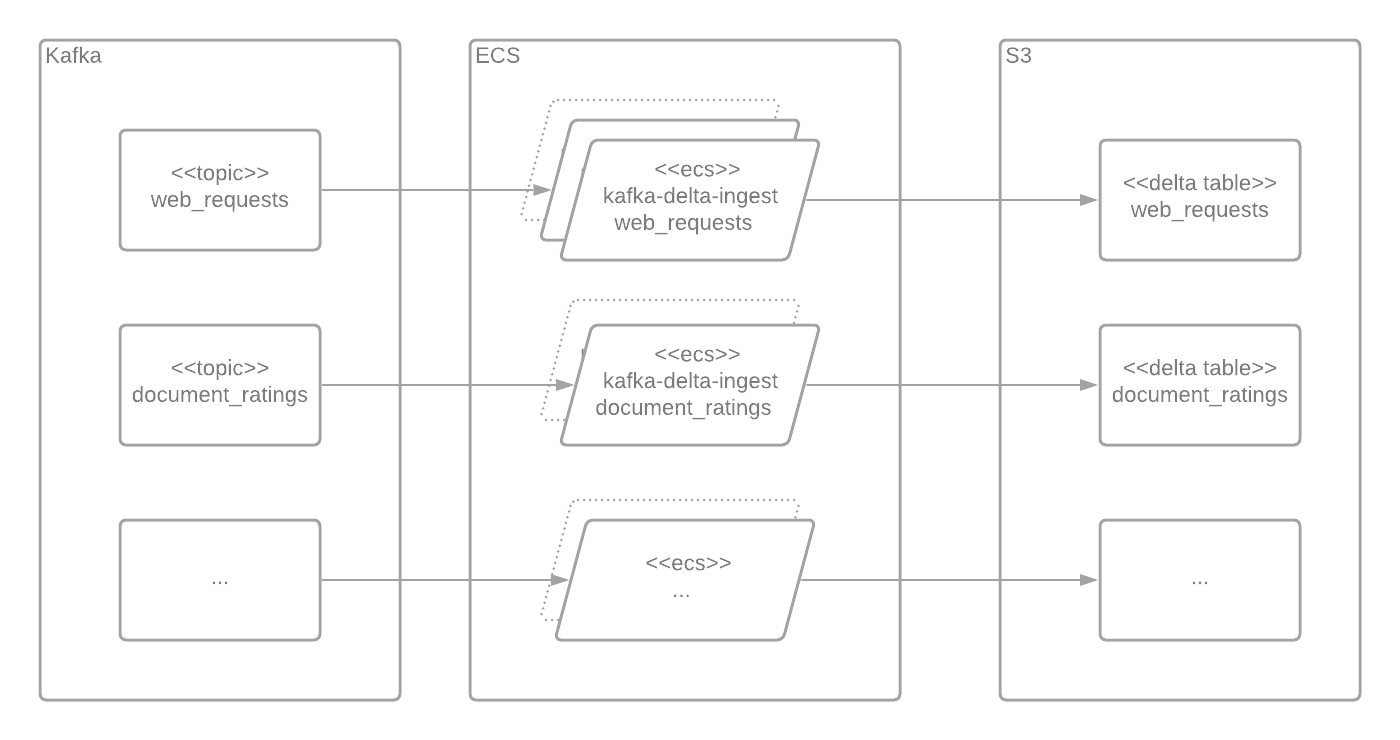
We have one Kafka Delta Ingest ECS service per topic-to-table ETL workload. Each service runs 24x7. We expect high volume topics to require more worker nodes and scale out and in occassionally, and low volume topics to require a single worker (more on that later).
💙
My favorite thing about Kafka Delta Ingest is its very narrow scope to optimize and replace a very common use case that you could support with Spark Structured Streaming, but much less efficiently. Basically, I love that we are creating a very specific tool for a very common need.
Compare/contrast of Kafka Delta Ingest vs Spark Structured Streaming:
- Kafka Delta Ingest ONLY supports Kafka as a source, whereas Spark Structured Streaming supports generic sources.
- Kafka Delta Ingest ONLY supports Delta Lake as a sink, whereas Spark Structured Streaming supports generic sinks.
- Kafka Delta Ingest ONLY supports JSON messages (so far), whereas Spark Structured Streaming supports a variety of formats.
- Unlike Spark Structured Streaming, Kafka Delta Ingest DOES NOT provide any facility for joining streams or computing aggregates.
- Kafka Delta Ingest is an application that makes strong assumptions about the source and sink and is only configurable via command line arguments, whereas Spark Structured Streaming is a library that you must write and compile code against to yield a jar that can then be hosted as a job.
- Kafka Delta Ingest is fully distributed and master-less - there is no “driver” node. Nodes can be spun up on a platform like ECS with little thought to coordination or special platform dependencies. A Spark Structured Streaming job must be launched on a platform like Databricks or EMR capable of running a Spark cluster.
Get Involved!
Contributions to Kafka Delta Ingest are very welcome and encouraged. Our core team has been focused on supporting our internal use case so far, but we would love to see Kafka Delta Ingest grow into a more well rounded solution. We have not been using the GitHub issue list for managing work just yet since we are mostly managing work internally until we have our primary workloads fully covered, but we will be paying much more attention to this channel in the very near future.
One especially interesting area for contribution is related to data format. A lot of folks are using Avro and Protobuf instead of JSON these days. We use JSON on all of our ingestion streams at the moment, but I’d love to see Avro and Protobuf support in Kafka Delta Ingest.
Another big contribution would be support for running periodically rather than continuously (24x7). I suspect a lot of folks have situations where Kafka is used as a buffer between data warehouse writes that occur periodically throughout the day. We have several low-volume topics that are not a good fit for 24x7 streaming because they only produce one or two messages per second. Having a 24x7 process buffer these topics in memory would be very awkward. It would make a lot more sense to let these buffer in Kafka and launch a periodic cron-style job to do the ETL a few times a day. This is similar to the “Trigger Once” capability in Spark Structured Streaming.
Another vector for contribution is delta-rs. Delta-rs is another Scribd sponsored open source project and is a key dependency of kafka-delta-ingest. Any write-oriented improvement accepted in delta-rs is Clikely to benefit kafka-delta-ingest.
Kafka Delta Ingest has a bright future ahead and I hope you’ll join us!