
Migrating streams from one Kafka cluster to another can be challenging, even more so when the migration is between two major versions, two different platforms, and from one datacenter to another. We managed to migrate Kafka to the Cloud on hard mode, without any downtime, and zero data loss. When we were first planning the migration, we joked that we wanted to avoid a single moment where we would try to swap Kafka all at once, like Indiana Jones tried in Raiders of the Lost Ark. In this post, I will share more about our Kafka migration to AWS MSK, and how we tried to avoid “Indiana Jones moments.”
Our goal was zero downtime and zero data loss. The approach we adopted was a gradual rollover method, one which worked so well that we will be re-using for moving Kafka traffic during future migrations.
Since we were talking about two very different Kafka environments, the changeover was a bit more involved than simply diverting traffic. Our legacy Kafka environment was version 0.10, the new environment ran 2.10. Our legacy cluster did not run with authentication, the new cluster required TLS client certificate-based authentication for producers and consumers. And while our legacy cluster was colocated in the same on-premise datacenter as the producers and consumers, the new Kafka cluster was to be hosted in AWS, in a region connected to the datacenter by a Direct Connect.
Our approach had four phases, which were executed in sequence:
- Send test writes to the new cluster: for each production message written to the old cluster, a test message would be written to the new cluster. This helped us verify our capacity plan and configuration.
- Double writes to both clusters: for each production message, writes would be issued to both clusters simultaneously, allowing downstream verification that both data streams were operating identically.
- Split writes to the new cluster at 10%: for one of every ten production messages, it would solely be written to the new cluster.
- Split writes to the new cluster at 100%: every production message would be written to the new environment.

The types of data passing through our clusters is basically analytics data. Conceptually it goes in “one direction”, from the producers to Kafka, from there consumers retrieve data and store it in our data warehouse. To support our gradual rollover approach, we needed to first update all our producers and consumers. Our producers needed to support both sending duplicate messages to both clusters. The consumers needed to support consuming from multiple clusters, joining the streams, and persisting the messages in the same (usual) location in HDFS.
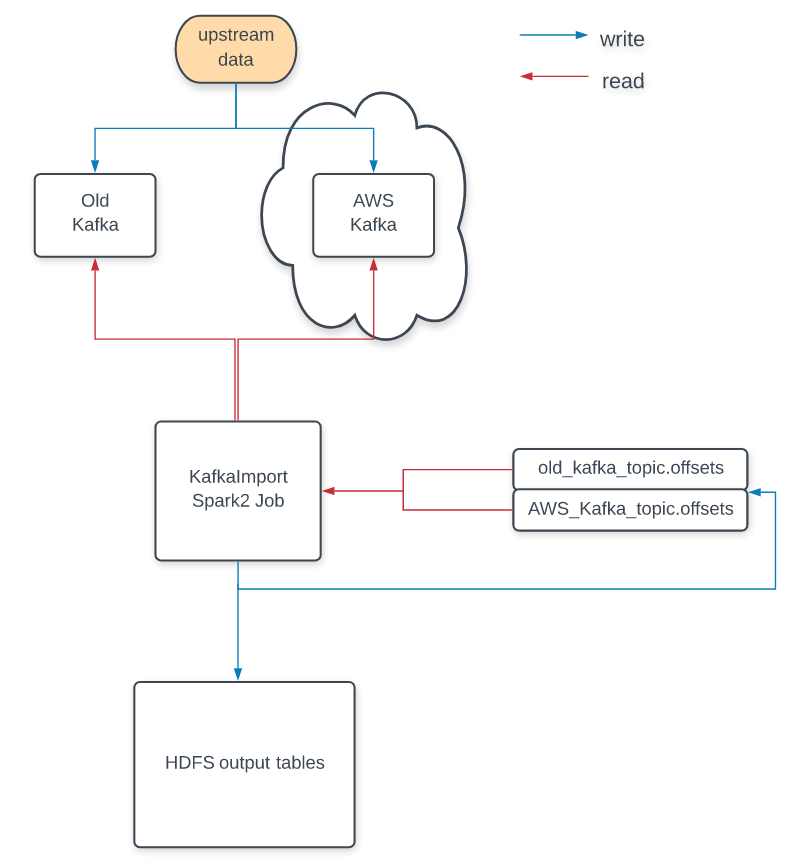 An example data flow.
An example data flow.
Once our producers and consumers were ready for the migration, we ran our test writes to verify that our new MSK-based cluster could handle the production traffic loads. As we expected, it handled everything smoothly! What we did not expect was the additional latency the second write call introduced. Since API endpoints needed to complete a synchronous “write” across the datacenter boundary into AWS before returning a 200 response, we saw the average response time for our endpoints go 50-80ms, with the 99% percentile taking almost 150-200ms longer! Fortunately, the added latency did not adversely impact this key-performance indicators (KPIs) of the producer application.
With the test write phase completed, we could finally start the actual migration of data. Although we had done end-to-end testing in our development environment, the gradual rollover of production was still essential. Therefore we continued with the next three phases:
- Double-writes
- Split-writes
- Single-writes
Double-writes
For this phase, the producers need to write each message twice, into both Kafka clusters. The production consumer remained the same, and continued to read messages from the old production cluster.
Writing data from all the hosts to both Kafka might seem to be redundant; however, It was critical to verify that all the hosts could write data into the new cluster, with its different authentication scheme and different version.
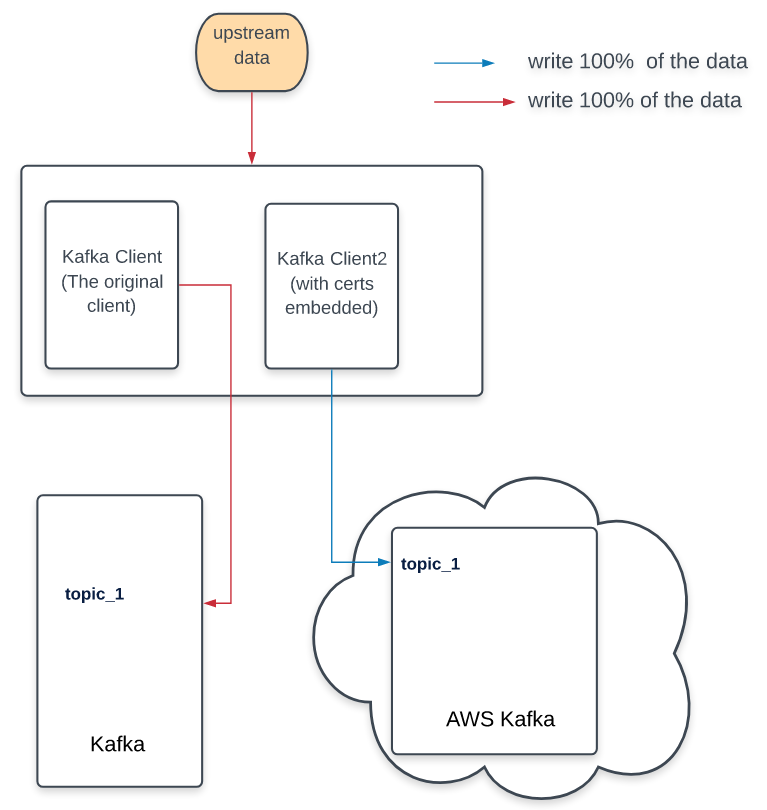
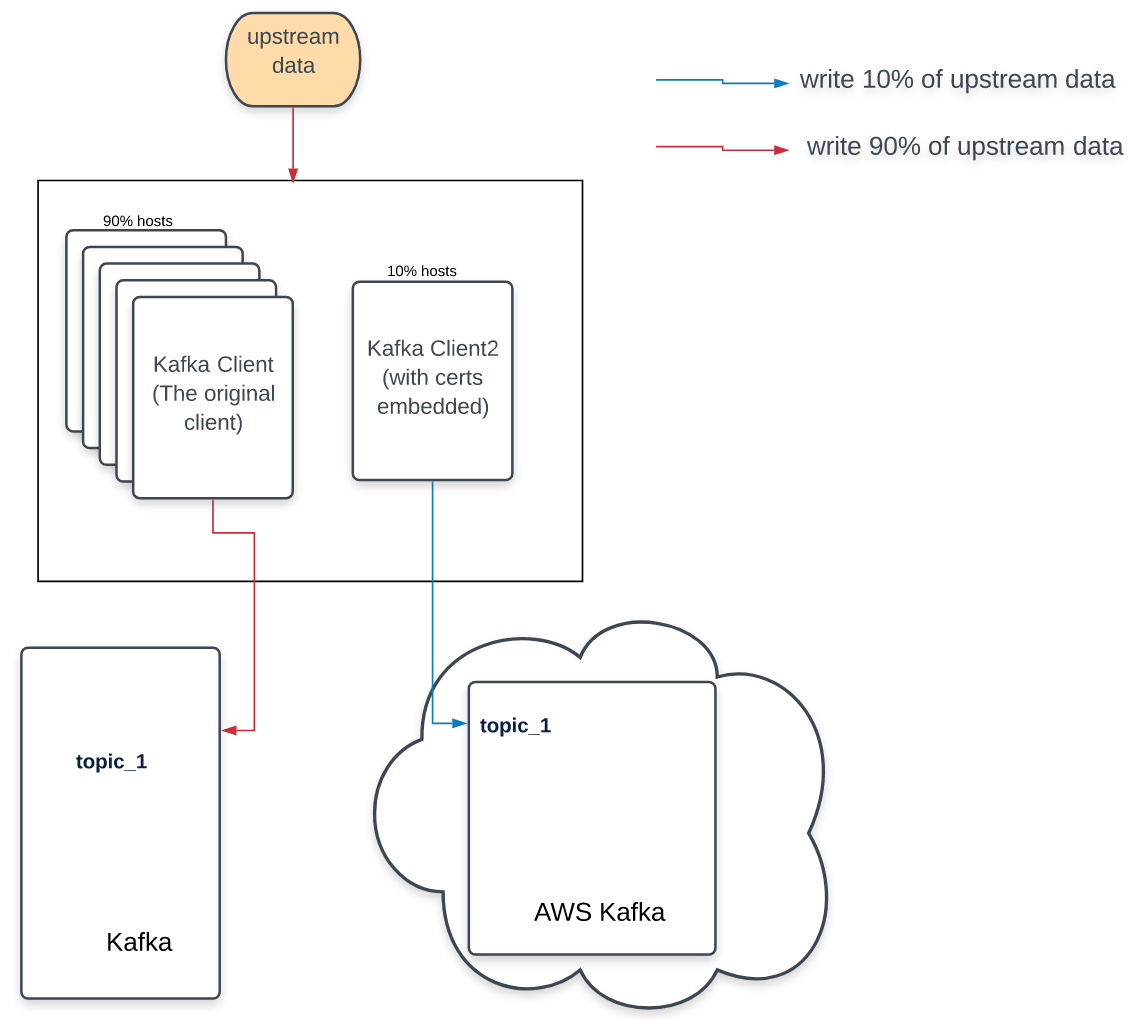
Split-write
After the double-write phase, we were fairly confident about using the new Kaka cluster. Nonetheless, switching clusters entirely in one shot would have been unnecessarily risky. We started with a gradual rollover of 10%, which we decided was an acceptable amount of messages to lose for a couple minutes if something were to go wrong in that “worst-case scenario.”
Our approach was to make it such that 10% of our hosts would write data to the new Kafka cluster. The rest of the hosts still wrote data into the old cluster. We structured the split on the host-level, rather than on each individual message to reduce the runtime complexity and potential debugging we might need to do in production. If something went wrong, we could comb through the logs of only a couple hosts, or quickly remove them from the load balancer.
To support this phase, the consumers had been deployed with their union logic enabled, allowing them to combine messages consumed from both clusters before writing them into long-term storage (HDFS).
Single-write
To complete the migration, all hosts were configured to send their traffic to the new Kafka cluster, although we left the consumer reading data from both clusters “just in case.”
Only after manual verification that the legacy Kafka cluster was receiving absolutely zero new messages, did we toggle the consumers to read from only one cluster: the new MSK-based Kafka cluster.
With 100% of Kafka producers and consumers interacting with the new cluster in AWS, we were able to tackle the most fun part of the project: decommissioning the old Kafka 0.10 cluster. We were not able to give it a viking’s funeral, but I would have liked to.
Unexpected Challenges
Zero data loss doesn’t mean that there were zero problems along the way. We did have some unexpected issues along the way. Fortunately no major issues manifested in production, we only saw a little bit more latency.
While we were testing the consumers with the new Kafka, I noticed some older
jobs, which were running under Apache Spark version
1, simply would not work with an MSK cluster. The version of
spark-streaming-kafka_2.10 uses the Kafka SimpleConsumer internally, which
does not accept Kafka properties or authentication parameters. Since we were
switching to TLS client certificate-based authentication, we had to overcome
this roadblock. As luck had it, we were already planning to upgrade those older
jobs to Spark 2, which includes Spark streaming changes among other
improvements, and the issue was resolved.
We also discovered some issues with the
ruby-kafka gem. While upgrading older
libraries across producers and consumers to support the newer MSK cluster, we
discovered that newer versions of the gem could not write messages to the old
Kafka cluster. This didn’t prevent our rollover of Ruby producers, but since
our older gem version could write to both clusters, we simply delayed the
upgrade of the ruby-kafka gem until the cluster rollover was complete.
Final Thoughts
Migrating Kafka clusters can be risky and stressful. Planning is very critical. Multiple producers and consumers can complicate major upgrades like this one. We created a central document for everybody to coordinate around, which captured the details of the different phases, along with the Jira tickets associated with each task. This proved to be incredibly valuable, and turned into our overall project dashboard for everybody involved.
In an ideal case, producers and consumers likely have not been changed in a while. They should carry on their jobs without constant supervision. While this is a good thing, it also means that there will be some code rot, and additional upgrades which should be considered along the way.
Finally, strong monitoring before the migration can begin is critical. We had set up Datadog dashboards for the legacy and future clusters before we even began the migration. This helped us understand what “normal” looked like for both clusters before we started making significant changes.
Rolling over to new Kafka clusters can be time consuming, but I think the extra time and patience to do it right is worth the effort.