
Scribd currently serves hundreds of Sidekiq jobs per second and has served 25 billion jobs since its adoption 2 years ago. Getting to this scale wasn’t easy. In this post, I’ll walk you through one of our first ever Sidekiq incidents and how we improved our Sidekiq implementation as a result of this incident.
The Incident
A large number of jobs for importing podcasts into Scribd were enqueued via Sidekiq. They took many hours to run and since they were added to our “default” queue, all our servers picked them up unlike if they were in the “bulk” queue. These jobs quickly starved all other jobs including the highest priority ones.
Detection: The incident was detected by an internal user noticing the queue build-up in Sidekiq’s web UI and a corresponding customer complaint that we linked back to this issue. Our systems were negatively affected for around 7 hours and the incident was noticed at the 6 hour mark.
Resolution: We ran a script on production to delete all existing jobs of this problematic worker from Sidekiq’s Redis instance and removed the batch job that was enqueuing them. We let the currently running jobs finish since killing them would require ssh-ing and running risky sudo commands on production servers.
What we learned
As pretty much our first ever major Sidekiq incident, we wrote an in-depth incident review that focused on 4 problem areas -
Quicker Detection
Our mean-time-to-detect this incident was way too high. To address this, we needed metrics and alerting. Since we have a Sidekiq Enterprise license, we simply integrated the Pro and Enterprise metrics into our existing Ruby Dogstatsd client.
We added the following Datadog monitors -
- X queue latency > Y value over past Z minutes
- % of job failures / total jobs > X% over last Y minutes
Quicker Debugging
To help add some debugging power to the monitors above, we also created some useful dashboards.
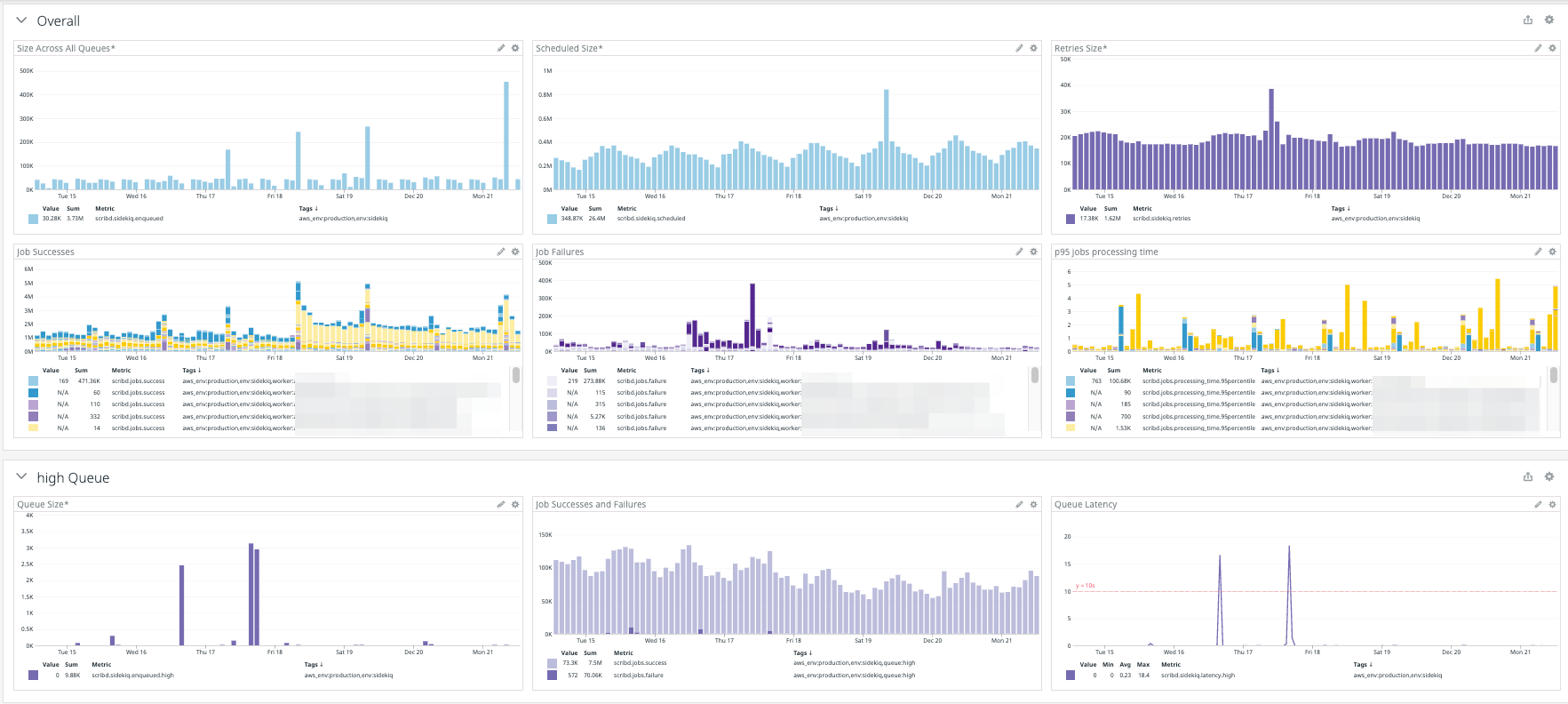
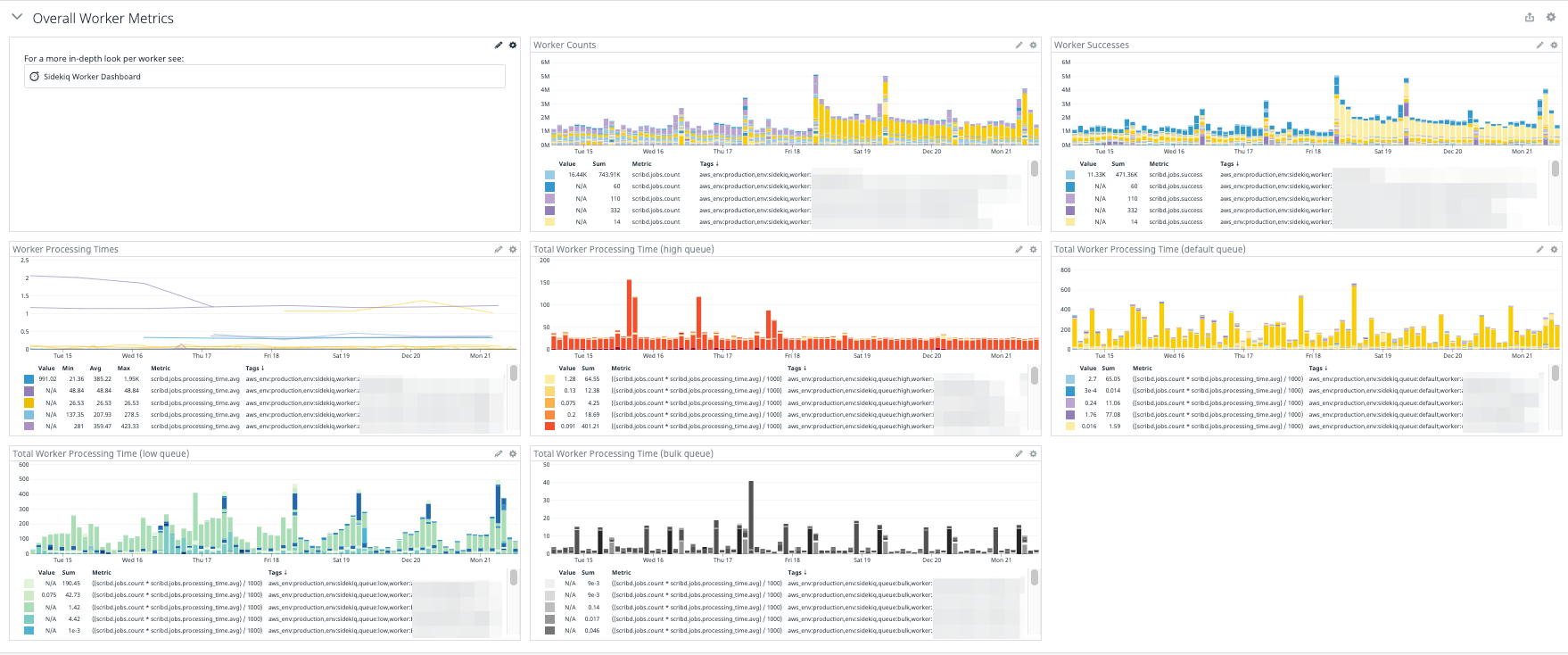
We added Sidekiq system-level, queue-level, and worker-level graphs that allow us to quickly go from system health to queue health to erroneous worker. From there, we can go over to the worker dashboard to find out whether the issue is around processing time or job failures and debug further in Sentry if needed.
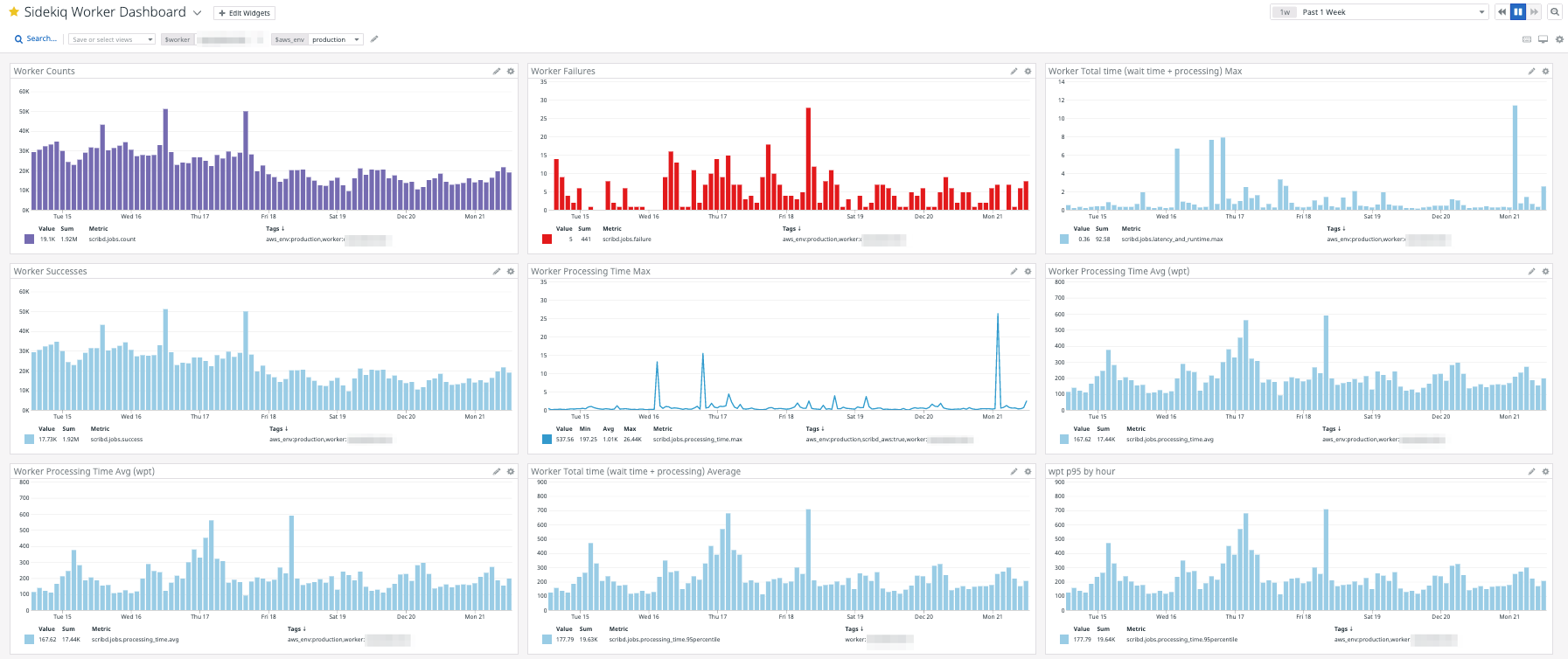
Later, as Scribd adopted Datadog further, we added APM for Sidekiq which covered a lot of the functionality we had but also added tracing of worker performance to further debug issues.
Quicker Resolution
Now that we’re able to quickly identify incidents and debug them, the next step is to resolve the issue.
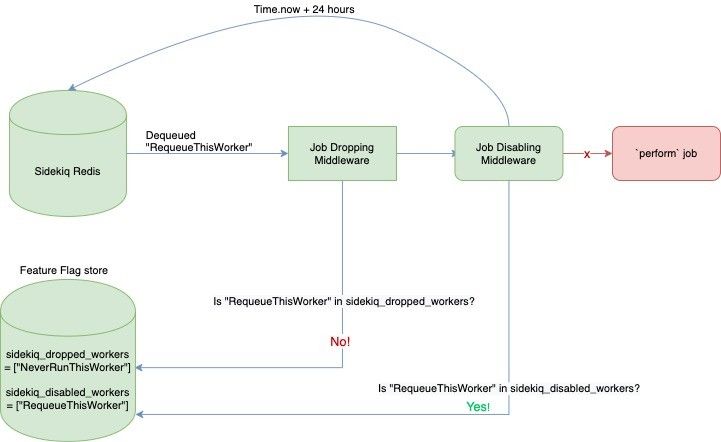
Something we learned from the incident was that editing Sidekiq Redis while it is already overloaded is a slow and highly error-prone process. To overcome this, we utilized Sidekiq’s ability to inject custom middlewares.
Job Dropping Middleware: We created a client middleware that would check a worker’s name against a live feature flag sidekiq_dropped_workers to decide if that worker should execute or be dropped pre-execution. This allowed us to “drain” a specific worker without having to manually edit Sidekiq Redis.
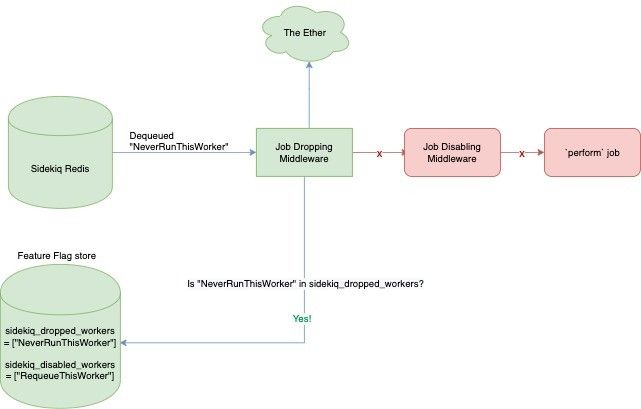
Job Disabling Middleware: In some cases, the worker’s issues may be easily resolvable in an upcoming deploy or re-enqueuing the workers may be extremely difficult. To address such a case, we introduced sidekiq_disabled_workers feature flag which utilized Sidekiq’s ScheduledSet to return those jobs to Redis to be run 24 hours later.
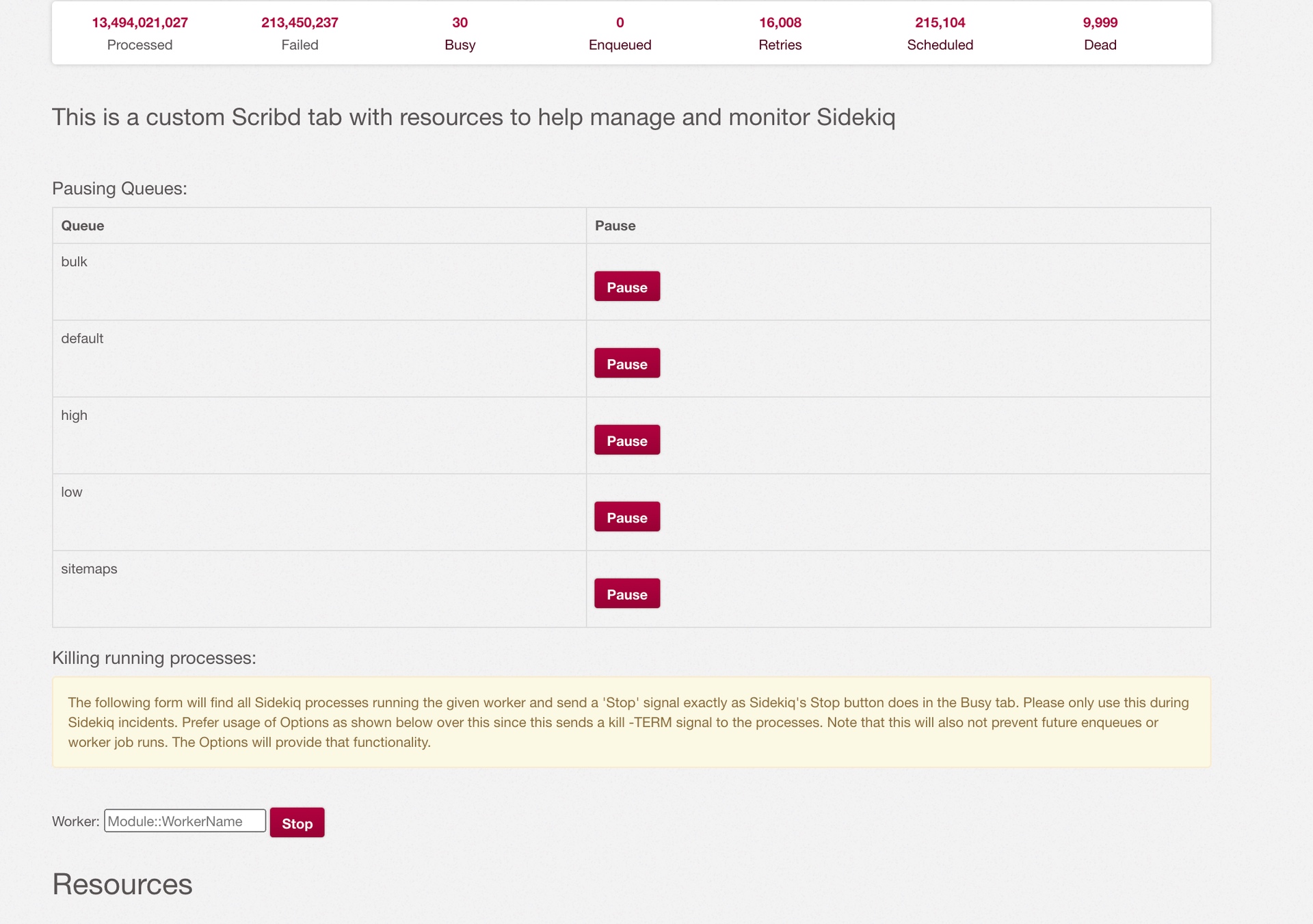
Job Termination Incidents Page: Finally, it was essential to find a way to quickly terminate existing problematic workers that have overtaken the queue. Sidekiq’s web UI is also quite extensible so we added a new web page called the “Incidents” tab which allows us to pause queues and terminate existing processes.
Future prevention
The team that added the problematic worker was not aware of Sidekiq’s shared model of usage and their worker’s ability to affect the system. They didn’t know when they should be using the default queue or the bulk queue.
Documentation: We created processing time and worker importance expectations for each queue. We listed best practices such as using timeouts, preferring multiple smaller jobs, idempotency, etc. and we linked to the Sidekiq documentation where we felt people may want more information.
Runbook: We also created an Incident Handling runbook that walks people through finding a problematic worker, debugging, and resolving the incident.

Guardrails: We also seriously considered adding timeouts which would forcefully terminate workers that go significantly over their queue’s expected processing time. However, we settled for a Sentry exception for workers that missed our guidelines auto-assigned to the team that owns the worker (via CODEOWNERS file). This approach has been sufficient for us so far.
Where we are now
Our systems are far from perfect but Sidekiq issues are now recognized within 5-10 minutes of their occurrence and usually resolved with no significant production impact.
When we addressed these incidents, we were running on data center servers but since then we’ve moved our workloads to AWS Fargate tasks. We’d like to add queue-based auto-scaling and the ability for degradation in database performances caused by Sidekiq workers to be recognizable and auto-resolve.