
Creating a monorepo to store DAGs is simple, easy to get started with, but unlikely to scale as DAGs and the number of developers working with them grows. In the Core Platform team, we’re bringing massive pre-existing DAGs into Airflow and want to support multiple teams and their orchestration needs in a manner that is simple and easy to operate.
In this post, I’ll share the approach we have taken to bring multi-repo DAG development to Apache Airflow and a new open source daemon I have written to make it possible.
Delivering DAGs
Every Airflow component expects the DAGs to present in a local DAG folder, accessed through a filesystem interface. There are 3 common approaches to meet this requirement:
- Bake DAGs into Airflow docker image
- Push DAGs to a networked filesystem like NFS and mount it as Airflow’s DAG folder
- Pull DAGs from the network into a local filesystem before starting Airflow components
Since Airflow is expecting the DAGs to be located in a single local folder, these approaches are all commonly implemented with a monorepo that is baked, pushed, or pulled.
Each of these approaches comes with its own set of trade-offs.
- Baking DAGs into Airflow images makes DAG deployment slow because you need to rebuild and release the new Airflow image for every DAG change.
- Managing a networked filesystem for DAG sync can be overkill from a performance and operations point of view, considering that Airflow only requires read access.
- Pulling DAGs requires some deployment or other coordination to ensure that the local filesystem has been populated with the appropriate changes before starting Airflow.
We decided to go with the “pull” model with AWS S3 as our “DAG source of truth.” S3 provides a highly available and easily managed location for our DAG store, but in order to support our desired multi-repo approach DAGs, we needed to build our own tooling to coordinate synchronizing the local DAG store with S3 objects from the multiple DAG repositories.
The tool we built, objinsync 1, is a stateless DAG sync daemon, which is deployed as a sidecar container. From Airflow’s point of view, the DAG folder is just a magical local folder that always contains the up to date DAG definitions assembled from multiple Git repos.
The full CI/CD pipeline
To demonstrate how the whole setup works end to end, I think it’s best to walk through the life cycle of a DAG file.
As shown below, S3 DAG bucket is acting as the bridge between Git repos and Airflow:
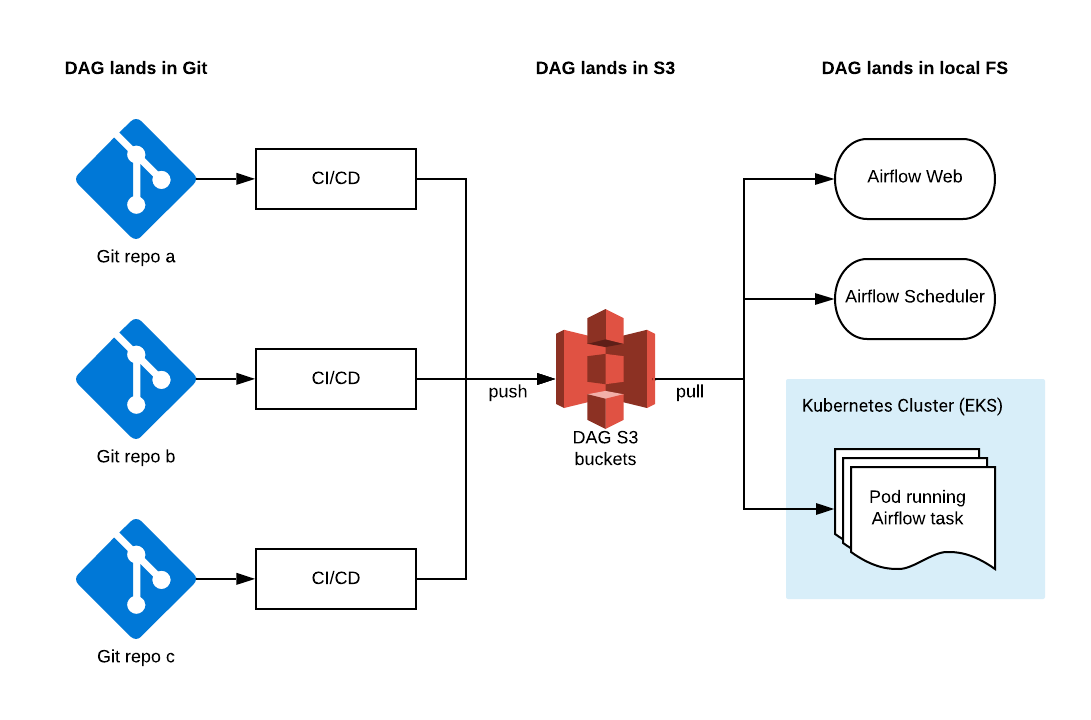
All CI/CD pipelines will publish their own DAG files into the same S3 bucket namespaced by the repo name. On the other end, objinsync deployed for each Airflow component will pull the latest DAG files into local filesystem for Airflow to consume.
Zooming out to the full picture, all DAG updates go through a multi-stage testing and promotion process before they eventually land in the production DAG S3 bucket:
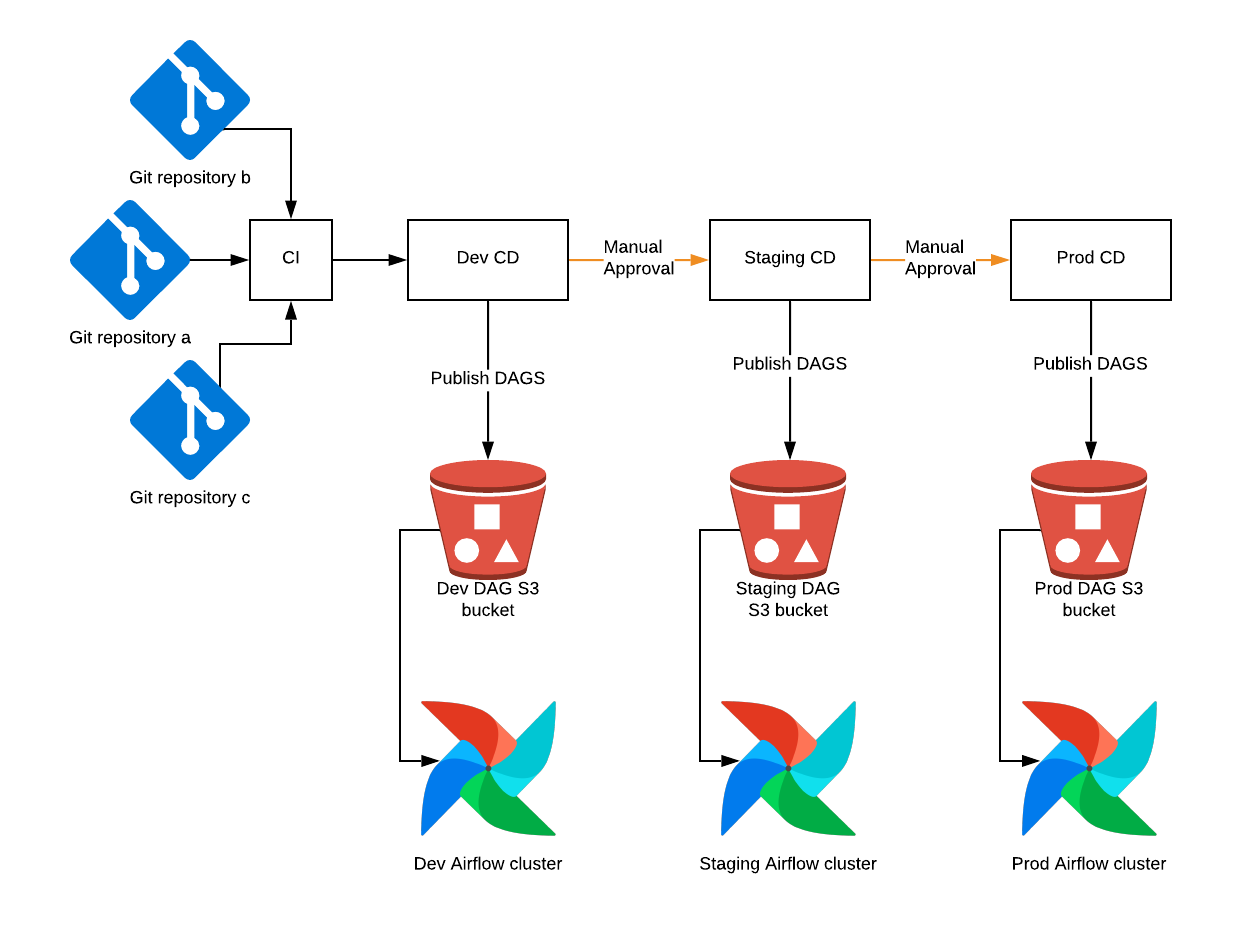
This gives our engineers the ability to test out changes without worrying about impacting production data pipelines.
Lastly, to simplify CI/CD setup, we built a small command line tool in Go to automate DAG to S3 release process. For any repo’s CI/CD pipeline, all an engineer has to do is adding a single step that runs the following command:
airflow-dag-push [dev,staging,production]
The airflow-dag-push tool will automatically scan for DAG files in a special
folder named workflow under the root source tree and upload them to the right
S3 bucket with the right key prefix based on the provided environment name and
environment variables injected by the CI/CD system.
Implementation details
Our airflow clusters are orchestrated using both ECS fargate and EKS. ECS is
used to run Airflow web server and scheduler while EKS is what’s powering
Airflow’s Kubernetes executor. Due to differences in different Airflow
components, we need to run the objinsync binary in two container orchestration
platforms with slightly different setups.
For daemon Airflow components like web server and scheduler, we run
objinsync in a continuous sync mode where it pulls incremental updates from
S3 to local filesystem every 5 seconds. This is implemented using the sidecar
container pattern. The DAG folder is mounted as a shared volume between the
Airflow web/scheduler container and objinsync container. The sidecar
objinsync container is setup to run the following command:
/bin/objinsync pull s3://<S3_DAG_BUCKET>/airflow_home/dags <YOUR_AIRFLOW_HOME>/dags
For other components like task instance pod that runs to completion, we run
objinsyncin pull once mode where it only pulls the required DAG from S3 once
before the Airflow component starts. This is implemented using Airflow K8S
executor’s builtin git sync container feature. We are effectively replacing git
invocation with objinsync in this case.
Environment variables for Airflow scheduler:
AIRFLOW__KUBERNETES__GIT_REPO=s3://<S3_DAG_BUCKET>/airflow_home/dags
AIRFLOW__KUBERNETES__GIT_SYNC_DEST=<YOUR_AIRFLOW_HOME>/dags
AIRFLOW__KUBERNETES__GIT_SYNC_ROOT=<YOUR_AIRFLOW_HOME>/dags
AIRFLOW__KUBERNETES__GIT_SYNC_CONTAINER_REPOSITORY=<DOCKER_REPO_FOR_GIT_SYNC_CONTAINER>
AIRFLOW__KUBERNETES__GIT_SYNC_CONTAINER_TAG=<DOCKER_TAG_FOR_GIT_SYNC_CONTAINER>
AIRFLOW__KUBERNETES__GIT_SYNC_RUN_AS_USER=0
AIRFLOW__KUBERNETES__GIT_DAGS_FOLDER_MOUNT_POINT=<YOUR_AIRFLOW_HOME>/dags
# dummy branch value to stop Airflow from complaining
AIRFLOW__KUBERNETES__GIT_BRANCH=dummy
Entry point for the git sync container image:
/bin/objinsync pull --once "${GIT_SYNC_REPO}" "${GIT_SYNC_DEST}"
objinsync is implemented in Go to keep memory footprint very low. It also means
the synchronization code can leverage the powerful parallelism and concurrency
primitives from the Go runtime for better performance.
Take away
Engineering is all about making the right trade-offs. I won’t claim what we have is the perfect solution for everyone, but I do believe it strikes a good balance between productivity, operability, and availability. If you have any questions regarding the setup, I am available in Airflow’s #airflow-creative slack channel under the handle “QP.” If you are not already part of the Airflow Slack community, you can get access via this link.
This is the second blog post from our series of data pipeline migration blog posts. The Core Platform is building scalable data and ML tools, with open source technology, to enable exciting new products at Scribd. If that sounds interesting to you, we’re hiring! :)
-
ObjInSync is a generic S3 to local filesystem sync daemon open sourced by Scribd. ↩