A few months ago, we came across a problem we need to upgrade our Kubernetes version in AWS EKS without having downtime. Getting the control plane upgraded without downtime was relatively easy, manual but easy. The bigger challenge was getting the physical worker node updated. We had to manually complete each of the following steps:
- Create a new worker node with latest configuration
- Put the old node in standby mode.
- Taint the old node to unschedulable
- Then wait for all our existing pods to die gracefully. In our case, we had some really long running pods, some of which took 20 hours or more to actually finish!
- Then detach and kill the old node.
While doing that we were thinking how about having an automated module, which will do all these work by just a button click. We are pleased to open source and share our terraform-aws-recycle-eks module which will do all these steps for us!
What Problem does it Solve
- Periodic recycling of old worker nodes. In fact we can create a lifecycle hook while creating the node and integrate the lifecycle hook with this module. That way the whole periodic recycling will be fully automated via the lifecycle hook and zero downtime via this module, no need for manual intervention at all.
- Minimal manual interventions while recycling a worker node.
- This can be integrated with SNS/Cloudwatch events, so that in the middle of the night if there is a CPU spike this Step-function can step up and create a new node while allowing the old node to die gracefully. That way all new tasks coming in can be catered in the new node reducing pressure on the existing node while we investigate the root cause and continue to be in service. There are plenty more use cases like this.
- This can make upgrading/patching of Kubernetes and eks worker nodes much easier
- Also this module has a custom label selector as an input, that will help the user to only wait for the pods that matters. Rest everything this module will ignore while waiting for the pods to gracefully finish
Components
Terraform
Terraform has always been our choice of tool for managing infrastructure, and using terraform for this module also gives us the opportunity to integrate this module with all other existing infra seamlessly.
Lambdas and Step Functions
Orchestrating Amazon Kubernetes Service (EKS) from AWS Lambda and Amazon EKS Node Drainer has already set a precedent that Lambdas can be a great tool to manage EKS clusters. However, Lambdas have one notable limitation in that they are very short lived. If we run all steps through a single Lambda function, it will eventually timeout while waiting for all existing pods to complete. So we need to split up the workflow into multiple Lambdas and manage their lifecycles through a workflow manager. This is where Step Functions enter the picture. Using a Step Function not only solves the problem of Lambda time-outs but also provides us an opportunity to extend this module to be triggered automatically based on events.
Design
- Create a Step Function that will consist of 4 Lambdas. This step function will handle the transfer of inputs across the Lambda functions.
- The first Lambda takes an instance id as an input, to put it in standby state. Using autoscaling api to automatically add a new instance to the group while putting the old instance to standby state. The old instance will get into “Standby” state only when the new instance is in fully “Inservice” state
- Taint this “Standby” node in EKS using K8S API in Lambda to prevent new pods from getting scheduled into this node
- Periodically use K8S API check for status of “stateful” pods on that node based on the label selector provided. Another Lambda will do that
- Once all stateful pods have completed on the node, i.e number of running pod reached 0, shut down that standby instance using AWS SDK via Lambda.
- We are not terminating the node, only shutting it down, just in case. In future releases, we will start terminating the nodes
Sample Execution
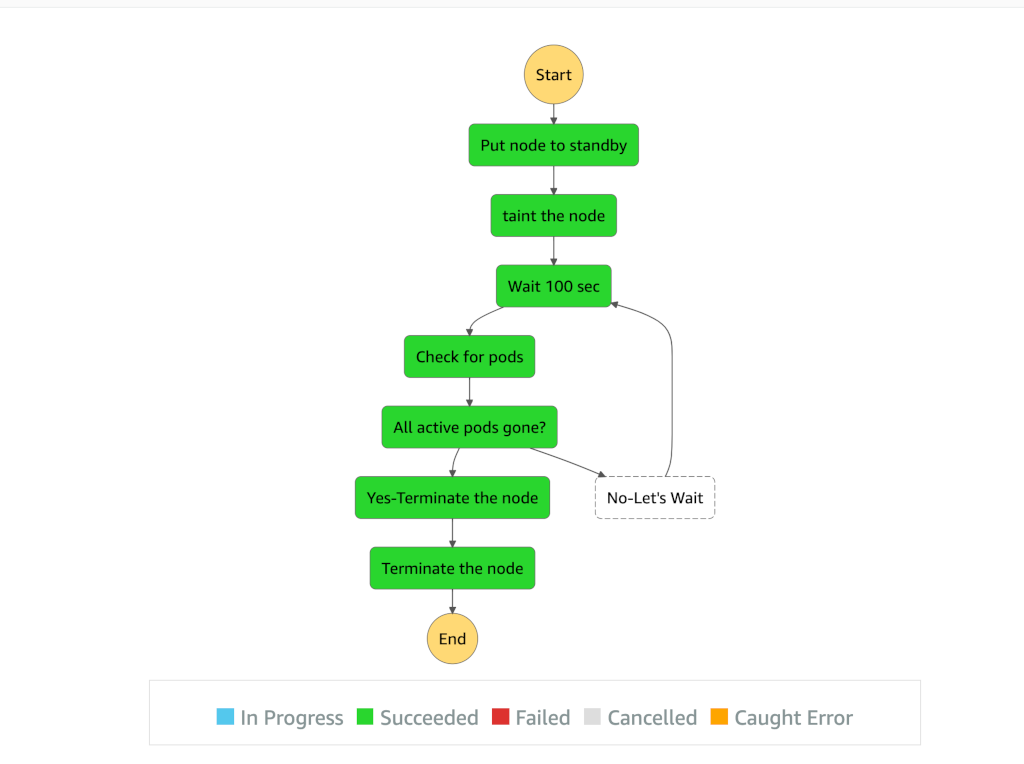
Future Enhancements
- First Lambda sleeps for arbitrary 300 seconds to ensure that the new node is in IN Service mode before putting the old node to StandBy mode. Ensure this programatically instead of sleeping.
- Use a common module for getting the access token.
- Better logging and exception handling
- Make use of namespace input while selecting the pods. Currently it checks for pods in all namespaces.
- Module doesn’t work without manual edit of
configmap/aws-auth. Find a terraform way to edit it.
Within Scribd’s Platform Engineering group we have a lot more services than people, so we’re always trying to find new ways to automate our infrastructure. If you’re interested in helping to build out scalable data platform to help change the world reads, come join us!